Linux Memory Allocation
27 Oct 2021
This post is my note while studying the sources. I do not own any of the below materials.
Library vs. System Call
System call: recall that the OS has user mode and kernel mode. When a process asks for hw resources, it requests this access from the OS. These requests are sent using system calls. To perform a system call, the process will need to context switch to kernel mode.
Library calls are simply calls to functions defined by a library. This does not say anything about if this call requires kernel mode or not. A library call may or may not require kernel calls.
The reason why people sometimes say library calls are faster than system calls is due to context switching. This is assuming not every library call requires system calls. For example, since not every malloc() requires mmap() or brk(), on average, calling malloc() is faster than mmap/brk(). Of course, if you decide to call mmap/brk() directly, you would not need to call them as often as malloc().
Memory allocation basics
When a process starts, it receives an initial allocation of memory up to a certain address, called the program break. Recall that these are virtual addresses. This means that virtual addresses beyond the page break are not mapped to any physical addresses yet.
To get more memory, the program can request more. The OS then maps more physical addresses to the process’ address space, thus increasing the program break.
Unix systems have two system calls to map in more memory: brk() and mmap().
brk() moves the program break to a specified address, effectively allocating or deallocating from the heap. sbrk() increments the program break. In older Unix systems, malloc() uses brk() exclusively. A couple of things to note:
- malloc() is a library call, where as brk() is a system call
- Not every malloc() call executes brk(). This is to reduce system call overhead. malloc() would first allocate a memory pool using brk() and use this pool for subsequent malloc() calls. malloc() calls brk() only if the pool is full.
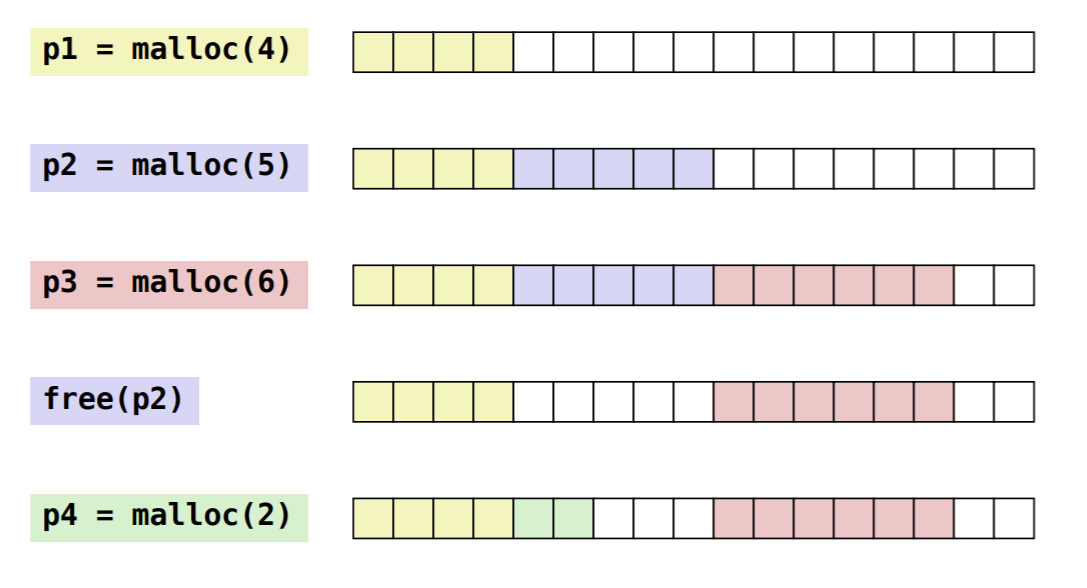
- malloc() using brk() has the problem of fragmentation. See figure below [3].
mmap() allows people to map in memory anywhere in the virtual address space. Memory mapped with mmap() does not have to be above the heap and does not relate to the program break, as shown in figure below [4].
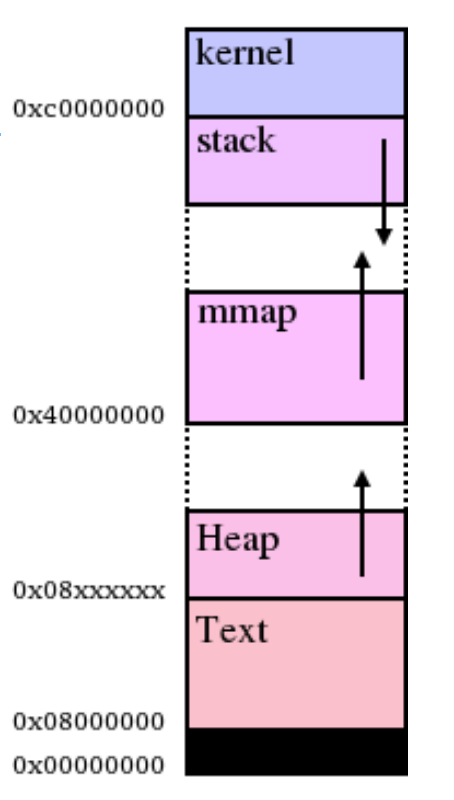
A quick note on the term memory arena. An arena is just a large, contiguous piece of memory you allocated [5]. Thus, as shown in the figure above, mmap() creates new memory arenas. You may want to give different processes separate arenas.
Here we are focusing on the anonymous mapping use case of mmap(). Another use case for mmap is to copy the content of a file into memory. To use anonymous mapping, pass -1 to mmap() in the file descriptor argument.
brk() vs mmap()
- mmaped memory is easier to manage, since different applications do not have to fight over the program break. With mmap, each app can do its own things in its mmaped region (as long as we don’t run out of memory).
- brk based malloc does not return the memory back to the OS immediately after free(). The allocator might give back memory only if there are no more in-use memory until the program break (fragmentation). unmap() returns memory to OS immediately.
- mmap() must be performed on page, 4kB granularity
- mmap() have been proven to show higher performance than brk. For example, Go uses mmap() exclusively.
- [1] says that today almost all large single memory allocations are done using mmap. Some libraries might still use brk() for small memory allocations.
- Some malloc implementations decide whether to use brk or mmap based on the size of the requested memory.
Sources
[1] https://utcc.utoronto.ca/~cks/space/blog/unix/SbrkVersusMmap
[2] https://developer.ibm.com/tutorials/l-memory/
[3] https://www.cs.cmu.edu/afs/cs/academic/class/15213-f09/www/lectures/16-dyn-mem.pdf
[4] https://lwn.net/Articles/91829/
[5] https://stackoverflow.com/questions/12825148/what-is-the-meaning-of-the-term-arena-in-relation-to-memory