Towards More Reliable CRM Agent
31 Dec 2025
TL;DR: Customer Relationship Management (CRM) is an important class of agentic workload. Automating CRM tasks with LLM agents can offer significant business value, but in practice, CRM agents often suffer from low reliability. I perform a series of information-preserving optimizations that make CRM tool outputs more token-efficient, achieving a nearly 3x reduction in token cost per record, improving agent reliability from 85.3% to 94.0%. This experiment highlights the need to rethink how we design system interfaces for agents.
Table of Contents
Background: The Challenge of Reliable CRM Agents
Customer Relationship Management (CRM) systems are the operational backbone for how organizations manage and analyze customer interactions. The promise of Large Language Model (LLM) agents to automate CRM tasks is significant: an ideal agent would learn from data, automate routine work, and proactively manage customer relationships to improve satisfaction and efficiency.
Salesforce introduced CRMArena, a benchmark that evaluates how well agents can perform professional CRM tasks. It provides agents with access to a realistic Salesforce platform and a set of tasks designed by CRM experts.
CRMArena specifies nine task categories. For this post, we narrow our focus to five categories that heavily rely on an agent’s ability to use tools, as opposed to pure natural language understanding:
- Handle Time Understanding
- Transfer Count Understanding
- Top Issue Identification
- Monthly Trend Analysis
- Best Region Identification
All nine task categories and example tasks are shown in the figure below (from the CRMArena paper).
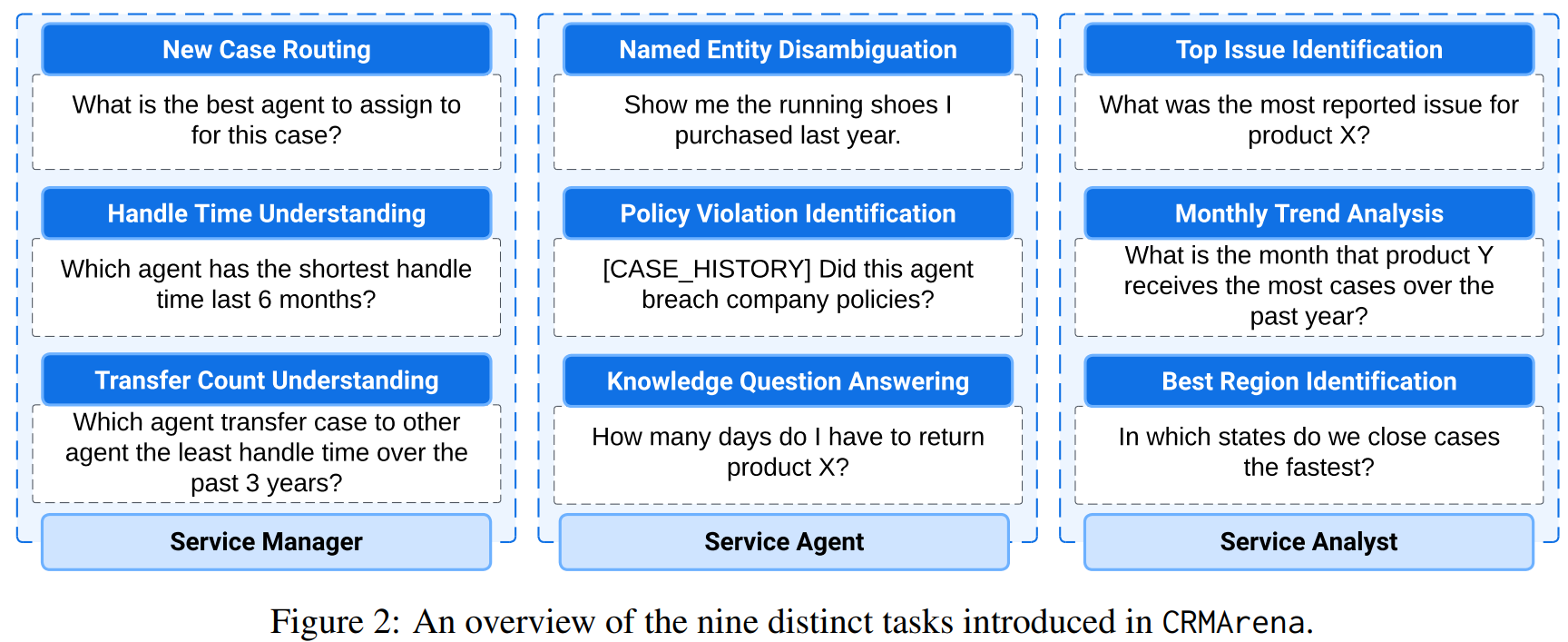
The agent is given an input task such as “Which agent has the shortest handle time during the past 6 months?” The agent is also provided a fixed set of functions designed specifically for the Salesforce CRM environment. A few examples (see the full paper Table 7 for full list):
| Functions | Description |
|---|---|
get_cases(start_date, end_date, agent_ids, case_ids, order_item_ids, issue_ids, statuses) |
Retrieves cases based on various filtering criteria. |
calculate_average_handle_time(cases) |
Calculates the average handle time for each agent based on a list of cases. |
calculate_region_average_closure_times(cases) |
Calculates the average closure times for cases grouped by region (shipping state). |
get_agent_handled_cases_by_period(start_date, end_date) |
Retrieves the number of cases handled by each agent within a specified time period |
Based on the given task, the agent can choose to invoke the available functions for a maximum of 20 turns. Correctness is evaluated based on the final answer provided by the agent.
Achieving high performance on this benchmark is important. As the CRMArena paper notes, “systems that can reliably complete tasks showcase direct business value in a popular work environment.” So the central goal of this post is to improve the reliability of such a CRM agent.
Agent Evaluation and Failure Analysis
To improve reliability, we first need to understand how and why agents fail. This requires a systematic analysis of their failure modes. Let’s start by measuring the success rate of the baseline agent1.

Triaging Failure Root Causes
We now have a bunch of failure traces to examine. We will extract common failure patterns and use them to decide how to optimize the agent (more on the Evaluate, Analyze, Optimize agent development loop).
Diagnosing the root cause of each failure requires specialized knowledge of CRM tasks: how to interpret trace files, what the correct tool-call sequence should be, and which failure patterns appear frequently.
I don’t want to manually look at these long agent failure trajectories and figure out what went wrong. So I built a triage agent specialized in diagnosing CRMArena failures. This triage agent was constructed using Socratic, an open-source tool I developed for iterative knowledge-base refinement.
3-minute video demo of how the triage agent is built:
The resulting knowledge base for the triage agent is here.
Failure Analysis
The triage agent helped me identify a dominant failure mode: 9 out of 15 failures stem from tool output truncation.
Why truncation occurs. Consider the task: “Which states have the quickest case closures in the past 6 months?” To answer this, the agent must:
- Retrieve all cases opened in the six-month window.
- Compute average closure time per state.
- Identify the minimum.
In a realistic CRM system, a six-month period can contain lots of cases. In this example, 198 cases exist in the query window. When get_cases() returns these records in standard JSON format, the output size exceeds the 10k character limit2, triggering truncation.
This pattern reveals a fundamental constraint: CRM tasks often require aggregating data across large amounts of data. When the tool output exceeds the available token budget, the agent receives incomplete information and computes incorrect results.
The bigger problem. Large result sets are common for analytical tasks like CRM. E.g., Monthly trend analysis requires time-series data across accounts; top-issue identification needs aggregation over ticket categories. Queries on a production CRM database can produce outputs measured in thousands of records and hundreds of kilobytes.
This is not a problem for traditional programs (non-agentic, deterministic scripts). Even when the amount of data is large, we can still reliably process it, since the analysis logic is deterministic.
Agents are different. The size of the output matters because of attention. When token costs per record are high, even moderately-sized datasets exceed context limits, forcing the agent to operate on partial data3. Even if it stays within the token limit, large amounts of output cause context rot and incur higher cost.
Example CRM agent failure trace
</div>
In the failure trace above, at line 97, get_cases() returns 198 cases in JSON format. The output is truncated mid-stream. The agent computes regional averages from the incomplete set, yielding NJ as the fastest state instead of the correct answer, OH.
The triage agent’s diagnosis:
**Surface-level failure**
- The run submitted `respond(\"NJ\")`, but `gt_answer` is `OH`.
- The `get_cases` tool output is explicitly truncated, so downstream aggregation is based on an incomplete case set.
**Most likely root cause**
- Root cause is **tool output truncation, causing incorrect regional
averages/min selection**: the agent computed
`calculate_region_average_closure_times` from a partial list of cases, so the "fastest" state came out as `NJ` instead of the true `OH`.
- This matches KB pattern CF-001 ("Tool output truncation leads to
incomplete aggregates").
Optimizing Token Efficiency
To address tool output truncation failures, the key idea is to redesign the output format that maximizes agent performance.
The get_cases() output uses standard JSON formatting. Each case object contains four fields with quoted keys and values, following conventional API design.
However, agents don’t require this strict JSON format, since LLMs are natural language processors.
Putting ourselves in the agent’s shoes (phrase from Anthropic blog), we ask: what information in the baseline JSON output is redundant and can be removed?
We start with the original object for a single case (77 tokens):
{"OwnerId": "005Ws000001xZcHIAU", "CreatedDate": "2021-11-26T09:30:00.000+0000", "ClosedDate": "2021-11-26T16:14:52.000+0000", "AccountId": "001Ws00003LjwjlIAB"}
The below figure shows a visualization of how this case object is tokenized by GPT models (OpenAI tokenizer). In other words, these tokens are what the underlying LLM model sees. The token breakdown can give us a good understanding of how to improve the token efficiency.

Step 1: Remove quotation marks. JSON requires quotes for syntactic parsing, but agents do not. Removing quotes reduces the token count to 74 without information loss:
{OwnerId: 005Ws000001xZcHIAU, CreatedDate: 2021-11-26T09:30:00.000+0000, ClosedDate: 2021-11-26T16:14:52.000+0000, AccountId: 001Ws00003LjwjlIAB}
Step 2: Remove field names from individual entries. When the order of each field is stable, repeating keys is redundant. We declare the format once at the top (similar to CSV headers), then provide only values. This reduces per-case cost to 61 tokens:
{005Ws000001xZcHIAU, 2021-11-26T09:30:00.000+0000, 2021-11-26T16:14:52.000+0000, 001Ws00003LjwjlIAB}

Step 3: Omit milliseconds and timezone when zero. The timestamps have .000+0000 suffixes. The default convention can be to omit these, with a fallback to full precision when values differ from zero. Result: 51 tokens:
{005Ws000001xZcHIAU, 2021-11-26T09:30:00, 2021-11-26T16:14:52, 001Ws00003LjwjlIAB}

Step 4: Base-delta compression for IDs. Taking a closer look at the AgentID and OwnerIDs, most IDs share an 11-character prefix within each ID type. For AccountIds, the prefix is 001Ws00003; for OwnerIds, it is 005Ws000001. We declare each prefix once, then show only the 7-character suffix per case. This yields 43 tokens per case: {xZcHIAU, 2021-11-26T09:30:00, 2021-11-26T16:14:52, LjwjlIAB}

Note: if the ID does not share the prefix, we pass the full ID to the agent as fallback.
This technique borrows from base-delta compression in CPU cache design: when values share a common prefix, storing a base plus deltas is more efficient than storing full values. The optimal prefix length is empirical and depends on the ID distribution in the specific CRM database.
Step 5: Base-delta compression for timestamps. Cases opened and closed on the same day share year-month-day components. When ClosedDate matches CreatedDate in date, we show only the time portion for ClosedDate.
Result is 36 tokens per case.
{xZcHIAU, 2021-11-26T09:30:00, 16:14:52, LjwjlIAB}

Step 6: Compact timestamp format. ISO 8601 uses YYYY-MM-DDTHH:MM:SS, which tokenizes inefficiently due to hyphens and colons. Replacing with YYYYMMDD-HHMMSS reduces tokens to 27:
{xZcHIAU, 20211126-093000, 161452, LjwjlIAB}

We achieve a 2.9× token reduction per case:
| Optimization | Tokens | Improvement |
|---|---|---|
| Baseline JSON | 79 | 1× |
| Remove quotes | 74 | 1.07× |
| Remove field names | 61 | 1.29× |
| Omit default ms/TZ | 51 | 1.55× |
| Base-delta IDs | 43 | 1.84× |
| Base-delta timestamps | 36 | 2.19× |
| Compact timestamp format | 27 | 2.93× |
The final optimized output of the same get_case() tool call looks like this:
"Format: {OwnerId, CreatedDate, ClosedDate, AccountId}.
Date fields are formatted as YYYYMMDD-HHMMSS when timezone and milliseconds are zero (e.g., '2023-01-15T09:30:00.000Z' becomes '20230115-093000').
For ClosedDate, if it shares the same date as CreatedDate, only the time portion (HHMMSS) is shown to reduce redundancy
(e.g., if CreatedDate is '20230115-093000' and ClosedDate is '20230115-153000', ClosedDate is shown as '153000').
[[xai1IAA, 20200817-080000, 20200818-122248, jwgYIAR],
[xZ9FIAU, 20200817-090000, 174513, jZAWIA3],
[xZxFIAU, 20200817-100000, 141012, j4oIIAR],
[xaRtIAI, 20200817-111500, 20200818-093406, jofoIAB],
[xaA9IAI, 20200818-093000, 172251, jofoIAB],
[xaq5IAA, 20200821-100000, 173211, jwgYIAR],
...,
[xTbjIAE, 20210214-140000, 203701, jNPXIA3]]"
Looks much cleaner.
Some notes:
- These optimizations are information-preserving: no data is lost. Whether they are lossless from the agent’s perspective, i.e., whether the agent can interpret the compressed format as reliably as JSON, requires empirical validation (next section).
- The 2.9x reduction is the best-case scenario. Several optimizations are opportunistic. E.g., Base-delta timestamps do not apply if createdDate and closedDate don’t share the same day.
- We apply the same idea to several other functions to make them more token-efficient. The full set of optimizations can be found in this repository, which contains the repo used for evaluations in this blog post.
Improved Results
With the above token efficiency optimizations, the train and test sets saw a 18% and 2% success rate improvement, respectively. Overall, the success rate improves from 85.3% to 94.0%. All results are the average of three trials.
The improvement is due to two reasons. First, the majority of previously truncated tool outputs are no longer truncated under the token-efficient format. Second, higher token efficiency reduces the LLM’s performance degradation due to long context.

Rethinking System Interfaces for Agents
Agents can benefit significantly from interfaces and systems designed specifically for agents. Traditional program interfaces (e.g., SQL, JSON) optimize for rigid parsing and stable schemas; token efficiency is largely irrelevant because a compiler or parser consumes bytes. But all agents operate over tokens, so the representation of data/information directly affects reliability. As the CRM results show, verbose formats increase truncation risk and degrade task accuracy.
This requires us to rethink how to design agent-native interfaces. E.g., Is it really optimal for agents to be writing SQL? Is bash the best way for agents to control computers? We have had these interfaces for a long time, and when agents came along, we kind of just said, “let’s make the agent use them just like we have been doing.” But does this really make sense?
This idea of new interfaces for new workloads is a new idea in computer systems. Operating systems introduced virtual memory so processes reason about stable pages rather than raw physical layout; the abstraction improves scalability and predictability. One can imagine a similar abstraction for agents that hides verbosity and exposes predictable, token-bounded views of data.
Discussions
“Just increase output token limit”. One may argue that we can just increase the output token limit from 10k characters. But this is not a scalable solution. Larger limits mean longer outputs to parse and reason over, which increases latency and error rates even when truncation is avoided.
Limitations of token-efficient output. That being said, the token efficiency optimizations also do not eliminate the scaling problem. If the dataset grows from 200 to e.g., 2000 cases, even compact representations will eventually hit token limits. Two potential strategies to mitigate this:
- Divide-and-conquer: divide large queries into smaller ones and aggregate results. Token-efficient output makes each partition more informative, improving the accuracy of partial views.
- Decomposition and delegation: architectures like subagents or tool-generating agents benefit from compact intermediate results, as they must parse, validate, and reason over outputs from delegated calls. Agent-oriented interfaces amplify the benefit of these techniques.
“We will have LLMs with longer context window”. Longer context windows address capacity but introduce two persistent costs: accuracy degradation due to context rot (the “lost in the middle” phenomenon), and token cost, which grows quadratically with the number of tokens.
Scope of evaluation. This study focuses on truncation-induced failures, which account for a significant fraction of errors in CRMArena. Other failure modes (lack of context, reasoning errors, tool selection mistakes) are not addressed here. Extending the approach to harder benchmarks (e.g., CRMArena Pro) or tasks requiring complex multi-tool orchestration would test the generality of agent-oriented interfaces beyond the CRM domain.
Footnotes
-
I randomly select a set of 50 CRMArena tasks, which were split into a training set for analysis (20 tasks) and a held-out test set for final evaluation (30 tasks). GPT-5.2 (reasoning effort = None) agent. Results are from the training set only. Average of 3 trials. ↩
-
The original CRMArena benchmark already restricts agent output length. I add a restriction on single tool output to 10k characters to avoid overly long outputs, a standard practice in agentic applications such as Codex. ↩
-
While alternative architectures exist (subagents, code-generating agents), token efficiency benefits all approaches: subagents must parse summaries or validate results, and code-generating agents inspect samples and debug traces. For the analytical aggregation tasks in CRMArena, agents primarily use direct reasoning over outputs. ↩