The Tail at Scale
20 Mar 2022
This post is my notes while going through [1]. See the Sources section for all sources used in this post. I do not own any of the materials.
The Big Ideas
- Like fault tolerance, latency variability cannot be 100% eliminated. How can we design systems to be tail-tolerant given components with high tails?
- Latency variability of individual components is magnified at the system/service level. See 100 machine example below.
- Two class of techniques
- Eliminating latency variability: break tasks into smaller pieces, synchronize background activities. Note that caching does not help with tail latency
- Living with it: hedged requests, tied requests; micro-partitions, selective replication, latency-induced probation. good-enough responses
Why Are Latency Variabilities Important?
Results need to be returned to the user within tens of milliseconds. Prior studies have reported that for the user to feel as if the system is reacting instantaneously, the response time needs to be lower than 100ms.
Why Do Latency Variabilities Exist?
Applications contend for shared resources in an unpredictable manner; Maintainance activities such as periodic log compactions and garbage collection; CPUs may throttle if too heated; SSD may need to perform garbage collection.
Queuing delays on a server before a request begins execution. Turns out that once the request begins execution, the latency variation drops significantly.
Latency variability of individual components is magnified at the system/service level. This is similar to fault tolerance, Based on [3], if components are connected in “series”, i.e. single failure causes system failure, then the system availability is computed by multiplying the availability of each component. E.g. 10*99.999% components = 99.999%^10 = 99.99% (10*3 nines = 2 nines).
If components are connected in “parallel”, e.g. replicated, then the system availability is 1 - system failure rate, where the system failure rate is the product of the failure rate of each component. E.g 2*95% components = 1 - 5%*5% = 99.75%.
To illustrate the effect scale on latency variability, the author gives the following example:
- Each server has 1 second 99th percentile latency. I.e. 1% of requests will have 1s latency.
- If the user only interacts with 1 machine, then 1% chance of the request taking 1s.
- If interacts with 100 machines in parallel, then in order for the latency to be lower than 1s, all 100 machines must respond within the 99th percentile latency. The probability of this is 1 - 99%^100 = 63%.
- (Another way to look at this question is, flipping an unfair coin with a 1% chance of head, what is the probability of flipping 100 times and not getting a single head?)
Try to Eliminate Latency Variability
- Give interactive workloads higher priority when scheduling. Google keeps its low-level queues (e.g. OS disk queue) short so that high-priority interactive requests can be served faster. ?How does this work? Why can’t I just bypass the queue? Perhaps Google does not want to evict workloads that are already running to save the context switch cost?
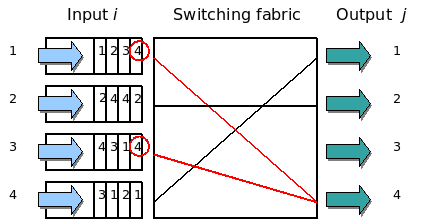
- Reduce head-of-line blocking (HOL): in the context of networking, HOL blocking occurs when a line of requests/packets is held up by the first request/packet in the line (Figure below [2]). In the context of distributed systems, since the system may run requests of different costs (runtime), long-running requests may block shorter requests. Google’s solution is to break down tasks into smaller requests.
- Background activities: synchronize across machines to execute them at the same time, ideally when there are few interactive requests.
- Distributed caching does not help tail latency, unless the entire working set can fit into the cache.
Live with Latency Variability
Just like fault tolerance, it is infeasible to completely eliminate all latency variations in the system. Categorize techniques into 1) short term, react in milliseconds 2) long term, tens of seconds.
Short term
Assuming we have multiple replicas of data items (for higher throughput/availability). We can use these replicas to improve tail latency as well. This also assumes that the cause of latency variation does not affect all replicas equally.
- Hedged requests: send requests to default replica, but after some delay (e.g. 95th percentile expected latency), send to other replicas as well. Use the result from the replica that responds first.
- Tied requests: since queuing plays a big role in latency variation, we can send the request to multiple servers (at the very start, not after some delay). When one of the servers starts executing this task (finished queuing), this server will send cancellation messages to the other servers also queuing this task.
- Alternative is to first probe the number of tasks queued in each server and submit to the least-loaded server. This paper argues that this is less effective than tied requests because 1) load levels can change between probe and submission 2) server load is hard to estimate 3) may create hot-spot on least-loaded server.
Long term
- Micro-partitions: divide tasks into fine partitions and have each server work on multiple partitions. This helps load balancing. Failure recovery speed can also be improved. ??? check how this works and connection with Spark. E.g. each BigTable machine manages 20-1000 tablets.
- Selective replication: detect or predict hot items and create additional replicas to distribute the load.
- Latency-induced probation: pause sending requests to slow machines. Continue to send shadow requests to these machines and observe their performance. If the cause of slowness is temporary, e.g. CPU spike, bring these machines back when performance recovers.
Some Google workloads allow “good-enough” responses, instead of requiring the perfect answer all the time. Occasionally returning “good-enough” responses can help with reducing tail latency.
Sources
[1] https://research.google/pubs/pub40801/
[2] https://en.wikipedia.org/wiki/Head-of-line_blocking
[3] http://www.webtorials.com/main/eduweb/manfr99/tutorial/five-nines/five-nines.pdf