Evolution and future directions of large-scale storage and computation systems at Google
22 Jan 2022
This post is my notes while going through [1]. see Sources section for all sources used in this post. I do not own any of the materials.
Note that this keynote was from 2010.
I start taking notes after the 38 minute mark, after the speaker finishes introducing mapreduce and BigTable. These specific tools will be studied in separate posts.
How can Raft afford to use a single master to serve all client requests? Does this not create a performance bottleneck? .
what are some typical read/write ratios for common distributed workloads? .
The Big Ideas
- Having a solid understanding of fundemental building blocks is critical for performing effective performance estimations. This include understanding common system numbers, design patterns, data structures, and key system components.
System Building Experiences
- Divide large systems into smaller services
- Simpler sw dev: few dependencies (?), easy to update individual services, run lots of experiments (?), reimplement service without affecting clients (?)
- Small teams can work independently
- e.g. a google.com search uses 100s of services
How exactly do services work? Why does services have these advantages?.
- Protocol description language (PDL) is a must
- Allows a program written in one language to communicate with another program written in an unknown language by offering a language independent interface to the underlying data. Commonly used in remote procedure calls. [2]
- Google’s PDL is called Protocol Buffers.
- High performance, compact binary format. Can also store data persistently.
- Designing Systems
- Critical skill: estimate performance of a system design
-
Prerequisites: solid understanding of the building blocks, aka. fundamentals.

Some things to note
- L1 is in the order of a couple of CPU cycle of 2GHz CPU
- L2/L1 is 10^1, main memory/L2 is 10^2, disk/main mem us 10^5
- Local network latency is on microsecond scale
- For the same amount of data, local network is ~50x slower than main mem
- DDR4=20GB/s, DDR3=10GB/s, HBM=200GB/s
- SSD BW=15GB/s, latency=20us; NVM BW=5GB/s, latency=300ns
- Practice back of the envelope calculations. (I wonder where I can find resources for this)
- Understand common systems, on the implementation level. Ex. core language libraries, data structures, protocol buffers, GFS, BigTable, MapReduce etc.
- Cannot perform effective back of the envelope calculations without solid knowledge of these basic components.
System Design Patterns
Single master, 1000s of workers
- Master has global view of the system to perform ex. load balancing, work scheduling.
- Must make sure that the client interaction with the master is minimal to avoid performance bottleneck. Client should interact with works directly.
- ex. GFS, BigTable, MapReduce
- Common to have hot standby master waiting to take over if primary master fails. The standby master will have replicated state, but not perform any actions until primary master fails.
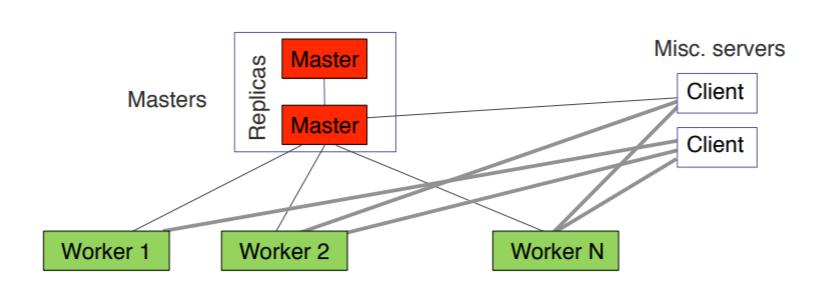
- Advantage: easier to reason about.
- Scales to 1000s of workers, but not 100,000s. (why not? what’s the bottleneck?)
Canary requests
- Problem: certain rare requests can cause receiving server to fail (e.g. due to software bugs). At large scale, cannot eliminate all through testing. If send requests to 1000s of machines, they can all crash.
- Solution: send a canary request to one machine. If the RPC is successful, then proceed to other machines.
-
This is a canary. Why is it called a canary request? Turns out, miners used to estimate the amount of toxic gas in a mine by sending in a canary first. [4]

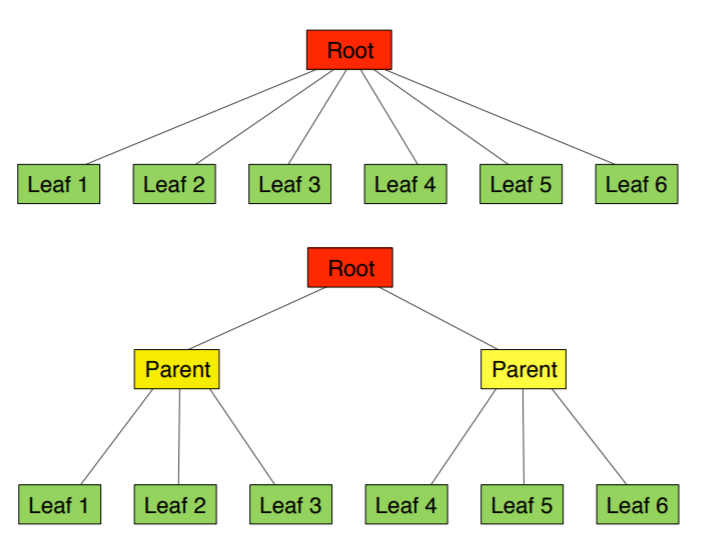
Tree Distribution of requests
- Problem: single machine sending 1000s of RPCs to leaf nodes overloads the NIC and CPU, degrading performance.
-
Solution: use tree distribution to reduce fan-in and spread processing amongst parents. Works best when parent nodes can trim/combine leaf node data. Even better if parent can be located on the same rack as leafs to reduce traffic.
Backup requests to reduce tail latency
- Problem: with 1000s of machine, few machines may stretch out latency tail. Solution is to send out backup requests to other replica nodes when few tasks remaining.
- e.g. MapReduce
Manage multiple piece of workloads per machine
- Problem: 1 workload per machine hard to load balance and slow recovery. Solution: each machine manage 10-100 unit of work. Fine-grained load balancing. When recovering, N machines each pick up 1 unit of work.
- e.g. MapReduce tasks, GFS chunks, Bigtable tablets
Split data by Range, not Hash
- Problem: need to spread large amount of key/values across N machines. Could use key hashing, but hard for user to reason about key/value locality.
- Alternative: divide key space into ranges. e.g. Bigtable tablets. User can control locality easier.
Make systems elastic
- Design system to shrink capacity during low load times and grow with the load.
- e.g. as load grows, use less CPU intensive algorithm alternatives, search less things, drop spelling correction tips.
Further Readings
- Protocol Buffers
Sources
[1] https://dl.acm.org/doi/10.1145/1807128.1807130
[2] https://en.wikipedia.org/wiki/Interface_description_language
[3] https://launchdarkly.com/blog/what-is-a-canary-release/
[4] By Forest and Kim Starr https://en.wikipedia.org/wiki/Domestic_canary#/media/File:YellowCanary.jpg