#24 The Google File System
22 Jan 2022
| Link | https://dl.acm.org/doi/10.1145/1165389.945450 |
| Year | SOSP 2003 |
The Big Ideas
- Designed for large sequential accesses and append.
- Break file into chunks, replicate, and distribute.
- Design pattern: single master multiple followers on two levels: master vs chunk servers and primary vs follower replicas.
- Decoupled metadata and data flow. Metadata only to master and data directly to chunk servers.
- The solution to data consistency is master-elected leader replica. To optimize for performance, GFS decoupled control and data flow for mutation requests. Since data is much larger than control, control is issued by primary using fanout and data is streamed to each replica.
- Provides weak data consistency guarantees. This is OK since Google can codesign applications and the filesystem.
- Design pattern: lease mechanism to reduce management overhead by offloading to a known safe server.
Backgrounds
The fundemental goal of large scale file system (or distributed systems in general) is to offer high aggregated performance using clusters of machines. But horizontal scaling is not easier. High performance usually means replication -> but requires extra work to ensure consistency and fault-tolerance -> lower performance.
^ widely accepted prior wisdom
This is a loop, or tradeoff that distributed systems must face.
Linux file append atomicity. How do they work? Atomicity guarantee? What are file namespaces
Details
Assumptions
(1) Hardware components fail on a regular basis (2) Files are large (3) Heavy large sequential reads + small random reads + large sequential appends (4) Heavy multi-client concurrent appends
Architecture and Operation
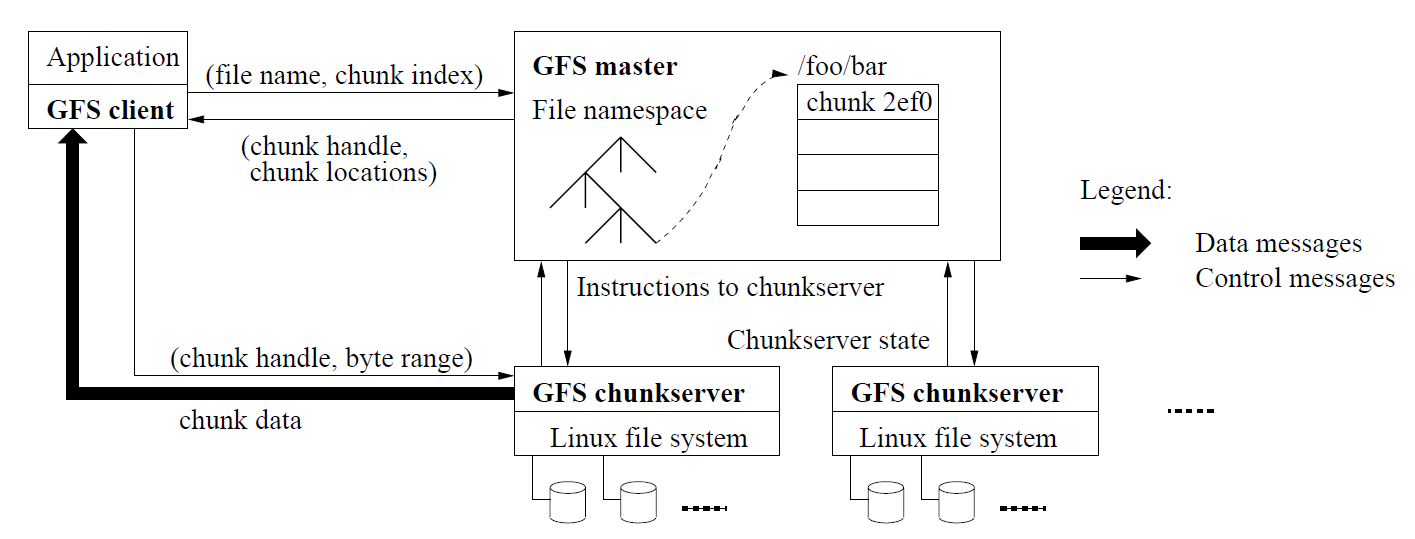
GFS uses a single master, multiple chunk servers, and multiple clients. Each file is divided into multiple 64MB chunks, which are replicated and stored across multiple chunk servers.
The master maintains only the system metadata while the chunk servers interact directly with the clients to handle data transfers. GFS is designed to minimize master interaction with the client to avoid performance bottlenecks on the master server. Separating metadata and data operations is a key insight of GFS, as these two types of data have very different access patterns. Google workloads typically require large and sequential data accesses while metadata operations are random and small.
Below are the data structures maintained in the master node, which will help us understand GFS’s operations [1].
struct master {
file files[filename]; // indexed by filename
log operation_log;
}
struct file {
string name;
chunk_hdl chunk_handles[];
}
struct chunk_hdl {
chunk_server chunk_servers[]; // list of chunk servers that has this chunk
string version_num;
node primary; // primary server for this chunk at current lease
time lease_exp;
}
Read operation
- The application issues a read request with the desired file name and offset.
- The GFS client translates offset into the chunk index in that file and sends it to GFS master.
- GFS master returns the chunk handle (which is a 64bit globally unique chunk ID) and chunk server locations to the client. Why does the client need the chunk handle? See next step.
- The GFS client then uses the chunk server location (probably IP addresses) to send the chunk read request to the chunk server. Since each chunk server contains multiple chunks, the client must send the chunk handle. Notice here the master is not involved anymore.
- Chunk server directly returns the requested data to the client.
Write Operation and Dataflow
Writing is more complex than reading, because it changes the data state. Since GFS uses replication, this means it needs to somehow support data consistency (later we will see that while GFS does provide some level of consistency, it is not very strong. However, the authors believe that it is strong ENOUGH if the applications are written in specific ways).
GFS provides consistency by selecting a primary replica, which can be viewed as a leader consensus approach. For each chunk, every so often, the master selects one of the replica chunk servers as this chunk’s primary and grants it a lease. The primary dictates the order of write operations for this chunk, and the follower replicas follow.
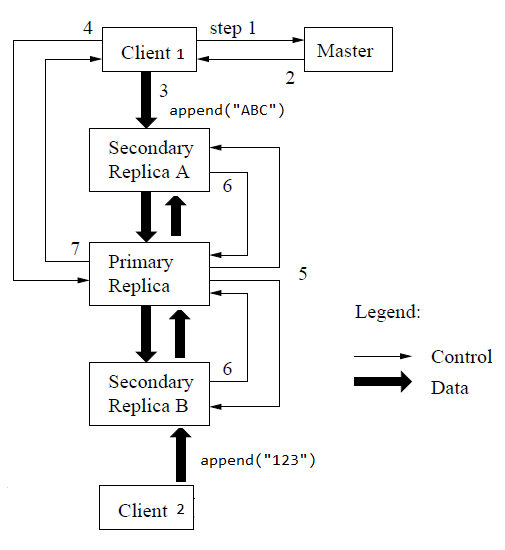
Now we are ready to take a look at the actions required for write operations. I found this to be one of the most confusing parts of this paper. Let us focus on append operations, which is the common case for GFS:
- The GFS client asks the master for the location of the primary and follower chunk servers for the last chunk in the file (Since this is append, the application does not need to provide an offset into the file, so the client does not need to provide the master a chunk index).
- The master replies with the location for ALL the replicas, including the primary and the secondaries. Why does the client need location of all replicas? Can the client not just send the data to one of the replicas? Yes, this is indeed what GFS does. However, the client uses the location of all replicas to find out the closest replica and only send data to that replica. This replica does NOT need to be the primary.
- This brings up another interesting design of GFS: write data and control are transferred separately to the replicas. Let us say that the client wishes to append the string “I am a little string floating in the sea of servers. Hope I end up at the right place.” That string itself is the data and the action append() is the control. I believe it is safe to assume that the data is typically much larger than the control.
- GFS first sends the data to the closet replica, which uses pipelining to forward the same data to the next replica. Note that when the replicas receive the data, they are temporarily stored in a buffer and not applied to the chunk yet.
- The question is: why this separation of data and control?
- Let us think about what happens if we also included data in the control channels. The obvious problem is even balanced network utilization, as the primary has a higher network fanout than the followers.
- What if we eliminated the control path and included control in the data path? In this case, consistency is not guaranteed anymore. It is easier to see this with 2 clients. In the figure below, we have a scenario where two clients are appending to the same chunk concurrently, but client 1 is closest to replica A and client 2 to replica B. This is allowed since the client can push data to the replicas in any order.
- In this case, replica A will likely receive
append("ABC")beforeappend("123")while replica B observes the opposite order. This is inconsistent as operations are performed out of order. Another way to look at this alternative is that, with the control path combined with the data path, the primary has no purpose anymore!
- Once all replicas receive the data, the client sends the append request (control) to the primary. At this moment, the primary may have received multiple control+data from different clients, so the primary just decides on a serial order to perform these appends and carries out the mutation to the chunks on disk.
- Next, the primary needs to communicate this serial order to the replicas via control messages. The paper does not explain how this is achieved, but I am guessing that during the data transfer phase, each piece of data is also attached with an identifier. This way, during the control phase, the primary can communicate the serial order to the replica by referring to these identifiers. e.g. append data2 (client1), data1 (client1), data5 (client2).
There is a lot more stuff going on in GFS, including Atomic Append, File Management, and Fault Tolerance. We might come back to study them in the future.
Further Readings
- Colossus. Why GFS getting replaced? See file:///C:/Users/kevinsong981/Downloads/1594204.1594206.pdf
Sources
[1] https://www.youtube.com/watch?v=EpIgvowZr00