#22 Demystifying the Performance of HPC Scientific Applications on NVM-based Memory Systems
18 Oct 2021
| Link | https://arxiv.org/abs/2002.06499 |
| Year | IPDPS 2020 |
Summary
This paper presents how NVM+DRAM affects the performance of several representative HPC applications in both Memory and App Direct modes. The authors identify two major NVM bottlenecks: write throttling and concurrency control. To resolve the latter problem, this paper proposes write-aware data placement.
The authors use Intel Processor Counter Monitor to collect memory events. I should check this out.
Details
Turns out NVM read and write have similar latencies. Writes have 3x lower bandwidth.
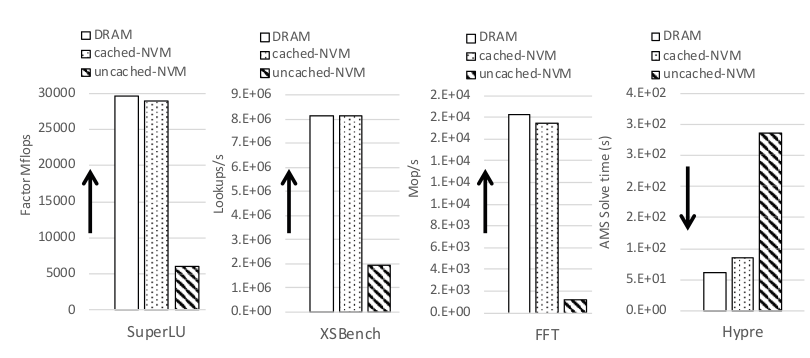
The paper first performs a comparison between DRAM only, NVM in Memory mode, and (I believe) NVM only in KMEM DAX mode. Note that this comparison is not very fair, since first, the NVM is not meant to replace DRAM. Second, all benchmarks have memory footprints smaller than the DRAM. So we expect the NVM to get destroyed, which is what happened.
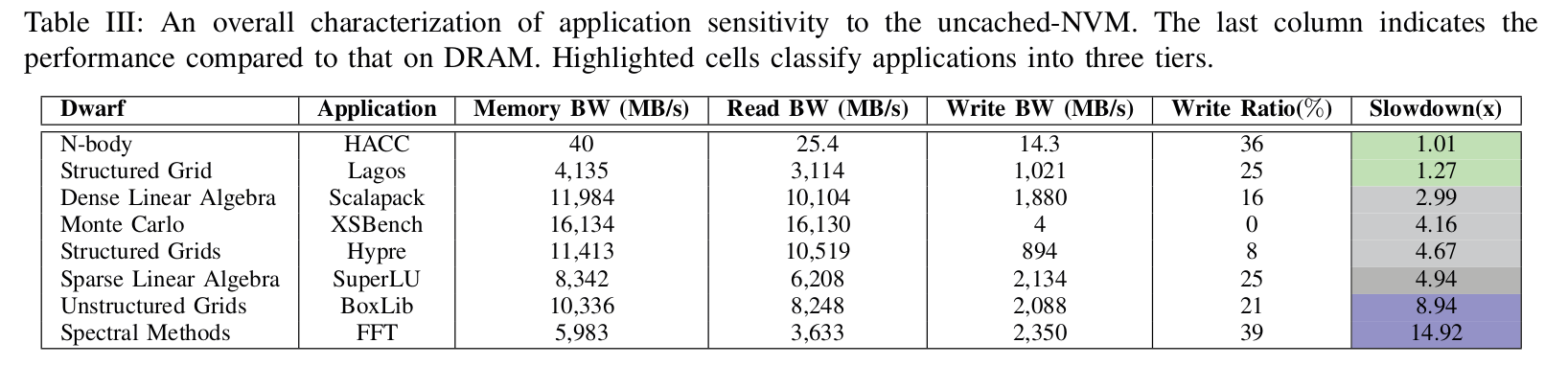
The next table is interesting. It shows some observations on why certain benchmarks perform worse when migrated to uncached-NVM (KMEM DAX). The two metrics that make an application perform badly on NVM are high memory BW and high write BW. BoxLib has both, so it is straight up gg. Between these two metrics, write BW seems to play a bigger role (see FFT).
Two main NVM bottlenecks:
-
Write throttling: its a known fact that NVM writes are slow (low BW). Worse yet, due to dependencies, slow writes may very likely become the bottleneck and slowdown reads! The paper observes a write BW threshold value (2GB/s), above which an execution phase will be significantly slowed down.
-
Concurrency divergence: it is also a known fact that NVM does not perform well if the number of threads is high (WPQ contentions). The paper makes an interesting observation where as concurrency increases, NVM read BW improves while write BW degrades.
The proposed solution to concurrency divergence: write-aware data placement. To reduce NVM writes, this approach keeps write intensive data in DRAM and place others in NVM. This sounds pretty obvious, but hey, simple (and effective) solutions are the best solutions.
The paper uses the Rthms [1] tool to identify write-intensive data structures. Then they manually modify the source code to place these data onto DRAM.
Questions
- What are the tradeoffs between NVM Memory mode vs. KMEM DAX mode? Ex. why did MemKeyDB choose KMEM DAX instead of memory mode?
- Memory mode requires no code changes, but I imagine KMEM DAX has more data migration flexibility since the application can decide whether to place the data in DRAM or NVM. KMEM DAX also offers a larger capacity.
- Ah, perhaps a more fundamental reason is that Memory mode performance degrades as the application consumes more memory. KMEM DAX performance should also decrease, but we might be able to design smart data migration schemes to improve performance.
- When the authors say “the Optane DC PMM is configured in AppDirect mode and exposed as NUMA nodes”, do they mean they are using
KMEM DAX mode?
- I believe so. The paper motions using the numactl. See https://pmem.io/2020/01/20/memkind-dax-kmem.html
- If that is the case, then this paper makes interesting comparisons between Memory Mode vs. KMEM DAX.
Comments/Thoughts
- No proposed solution for write throttling.
- How good is Memory mode? If Memory mode is good enough for apps that require more DRAM capacity, then we have the perfect solution since it requires zero code changes. I imagine that is not the case.
Sources
[1] https://dl.acm.org/doi/pdf/10.1145/3156685.3092273