#21 Scaling Memcache at Facebook
16 Oct 2021
| Link | https://www.usenix.org/system/files/conference/nsdi13/nsdi13-final170_update.pdf |
| Year | NSDI 2013 |
Summary
This paper describes insights Facebook gained from modifying the open source version of memcached to build a distributed key-value cache at a global scale. It is interesting to see that similar to Redis, FB was willing to sacrifice consistency for performance.
Background
Look-aside vs inline caching
- Look-aside: upon a cache miss, the client retrieves data from the database. Application has more control over caching.
- Inline: upon a miss, the cache is responsible to retrieve the data.
UDP vs TCP
- UDP is connectionless. Packets are sent in arbitrary order and error recovery is not performed. No handshake, no acknowledgment. Thus, UDP is more light weight [1]. Figure is from [2].

Details
Interestingly, Facebook users generate an order of magnitude more read requests than write. Thus, Facebook’s memcache is read-optimized. Amazon is the opposite, which is write dominated.
Facebook uses memcache as a demand-filled look-aside cache, as shown in the figure below. Upon a read miss, the web server retrieves data from db and adds the entry to the cache. Upon a write, the server directly writes to the db and deletes the entry in cache. The paper says they delete instead of update because deletion are idempotent, which means f(x) == f(f(x)). I am guessing they mean they do not have to worry about data consistency.
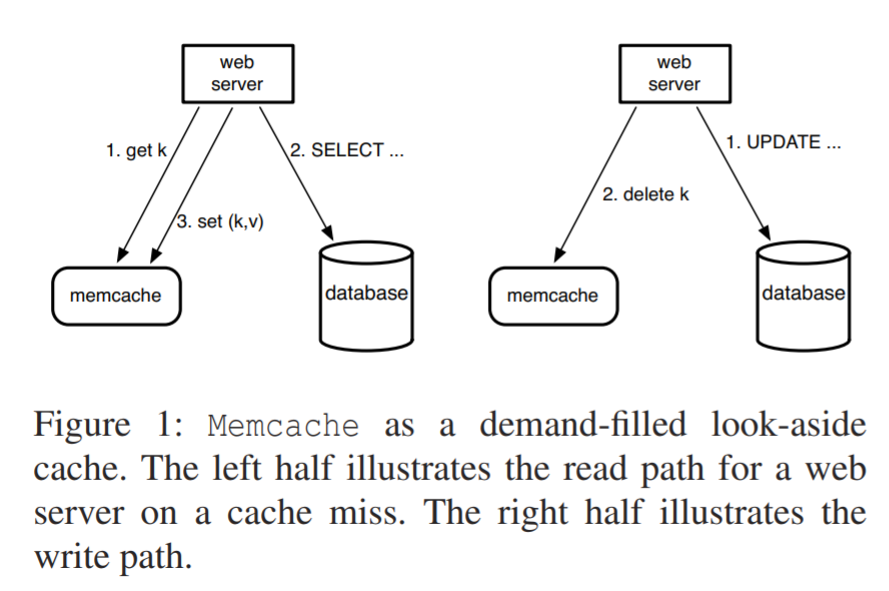
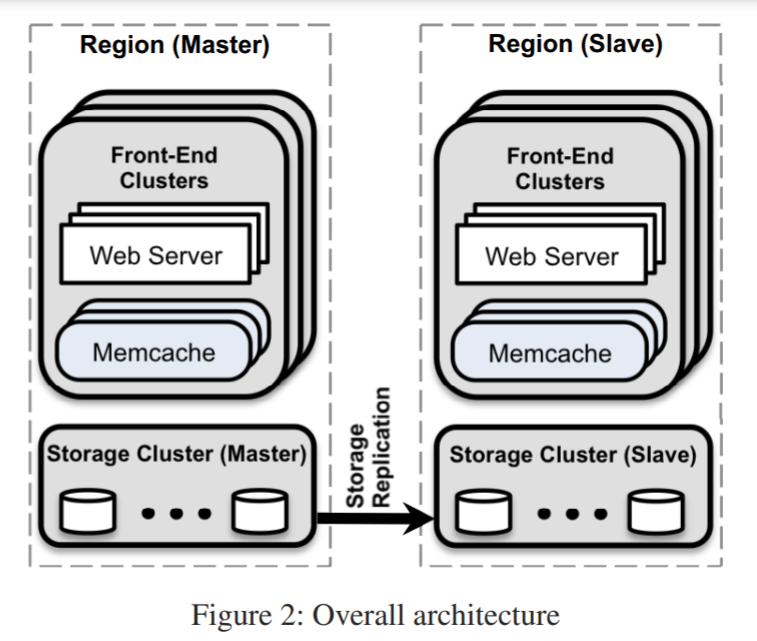
The below figure shows FB’s memcache architecture. Each region is placed in a different geographical area. Within each region, there are multiple web server + memcache clusters and one shared storage cluster.
Within a Cluster
Two main design goals: reducing read latency and load due to cache miss.
Reducing read latency:
- Loading 1 FB popular page => on average 521 cache fetches. This number probably is higher today.
- Then main strategy is to focus on memcache client (web servers that send read requests). 1) construct DAG in client to represent data dependencies (ex. GET A; GET user[A]). Use the DAG to maximize fetch concurrency. 2) Use UDP for read requests since reads have lower reliability requirements. Use TCP for write and delete.
- A key insight is that keeping the clients stateless makes development and deployment simple.
- FB team decided to move complexity in client rather than memcached to keep it simple for other use cases.
- Since keys are distributed across servers, one client may need to talk with multiple memcache servers. This may casue the problem known as incast congestion, where multiple parallel client requests significantly degrade network performance [3]. FB’s solution is slowdown the clients by controlling the number of outstanding requests.
Reducing Load: Load here refers to database requests when cache misses. Three techniques:
- Leases
- memcache instances give out leases to clients for the client to set data after it
experienced a miss. This prevents the problem of stale sets, illustrated below [4]:
key 'k' not in cache C1 get(k), misses C1 reads v1 from DB as the value of k C2 writes k = v2 in DB C2 delete(k) (recall that any DB writes will invalidate key in cache) C1 set(k, v1) # now mc has stale data, since delete(k) has already happened # will stay stale indefinitely until k is next written. # (I believe even though k is deleted from the cache by C2, # C1's set adds k back into the cache after not finding the key.Leases are bound with specific keys. Thus, k’s lease would prevent C1 from performing the stale set.
- Leases also mitigate thundering herd, which happens when many clients attempt to read the same data for a key not present in the cache. This will cause heavy database traffic[4]. Leases prevent this by only allows one request of the same key every ex. 10 seconds.
- FB also uses the idea of victim buffer in computer architecture to give recently deleted items a second chance. That is, upon a cache miss, it is acceptable for the client to receive a slightly stale data and avoid accessing the db.
- memcache instances give out leases to clients for the client to set data after it
experienced a miss. This prevents the problem of stale sets, illustrated below [4]:
- Memcache pools
- Partition servers in a cluster into pools (each pool contains multiple servers). Use various pools to optimize keys with different characteristics. Ex. provision small pool for keys that have low miss costs.
- Replication within pools
- Replicate a category of keys within a pool when the app fetches many keys in parallel and one server cannot handle the request rate.
- FB chose replication over splitting the keys because… I don’t quite understand the motivation behind this decision.
Used to improve latency and efficiency.
Single Server Optimizations
An interesting optimization is FB’s adaptive slab allocator. The memory is divided into slab classes, each of which will contain objects of a specific size range. FB dynamically identifies slab classes that require more memory and provides it with more space.
The original memcached lazily evicts expired cache items (existed longer than TTL) by only evicting them when it receives a get request for those items. This wastes memory for short lived keys. FB places short lived keys in a separate structure and proactively evicts them.
Questions
What does sacrificing slight consistency mean for the end user? I imagine this would look something like: Alice made a new post, but Bob cannot see it yet. After a couple of refreshes, the update appears.
Comments/Thoughts
- I wonder what have changed in FB’s memcache from 2013 to today. Need to do more readings.
- Some of these optimizations (ex. client sliding window to reduce incast congestion) sound pretty straight forward. I wonder if this is because there are hidden complexities or the fact that this paper is from 2013.
- Unfortunately, the paper does not provide details on a couple of insights mentioned in the conclusion, such as separating cache and storage systems and using stateless components. Welp, industry secrets I guess.
Further Readings/Topics
- Consistent hashing
- How proxy works
- How daemon works
Sources
[1] https://www.lifesize.com/en/blog/tcp-vs-udp/#:~:text=TCP%20is%20a%20connection%2Doriented,is%20only%20possible%20with%20TCP.
[2] https://www.reddit.com/r/ProgrammerHumor/comments/9gcwgw/tcp_vs_udp/
[3] https://conferences.sigcomm.org/co-next/2010/CoNEXT_papers/13-Wu.pdf
[4] https://timilearning.com/posts/mit-6.824/lecture-16-memcache-at-facebook/#architecture