#16 MapReduce: Simplified Data Processing on Large Clusters
28 Jun 2021
| Link | https://static.googleusercontent.com/media/research.google.com/en//archive/mapreduce-osdi04.pdf |
| Year | OSDI 2004 |
MapReduce is a programming model and implementation for processing large amounts of data in distributed computing systems. MapReduce makes programming compute clusters easy, as the user does not have to worry (too much) about how the tasks are parallelized among the compute clusters. The programmer defines two functions, map and reduce. The MapReduce tool then transparently distributes these two functions to various compute workers. The overall function takes in a set of input key/value pairs and produces a set of output key/value pairs, as shown in Listing 2. Note that the input and output key/value pairs are from different domains (1 vs 2). Map performs the domain conversion.
An example is shown in Listing 1. Here we have bunch of documents, and we wish to count the occurences of every word in these documents. (k1, v1) in this case are (doc_name, doc_content). Map converts this into (k2, v2) which is (word, occurence). In this example, v2 is always 1. Reduce receives a list of 1’s and accumulate them.
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
Listing 1: Word counting example [1].
map (k1,v1) --> list(k2,v2)
reduce (k2,list(v2)) --> list(v2)
Listing 2: Mapreduce type mappings [1].
Figure 1 shows MapReduce’s execution overview. The (integers) represent the sequence of actions when the user starts the mapreduce execution. The tool first partitions the input dataset into M splits in order to distribute the work to the number of map workers. The intermediate keys are partitioned into R splits to distribute among the reduce workers. For example, we can have 10,000 input documents, 100 map workers, 100 reduce workers, and 20,000 unique words. If we let M=10,000, then we are splitting the input documents into 10,000 sets, each containing 1 document. These 10,000 tasks are then distributed to the 100 map workers. If we let R=10,000, then each intermediate key set contains 2 words. Then 10,000 reduce tasks are then distributed to the 100 reduce workers.
MapReduce tries to assign map tasks to machines that contains the corresponding input data locally to reduce network traffic. The map workers write their output intermediate results to their local disks and send these locations to the master. The master forwards these locations to reduce workers, which reads the intermediate results remotely. The reduce workers will first sort the intermediate data by keys (ex. group same words together).
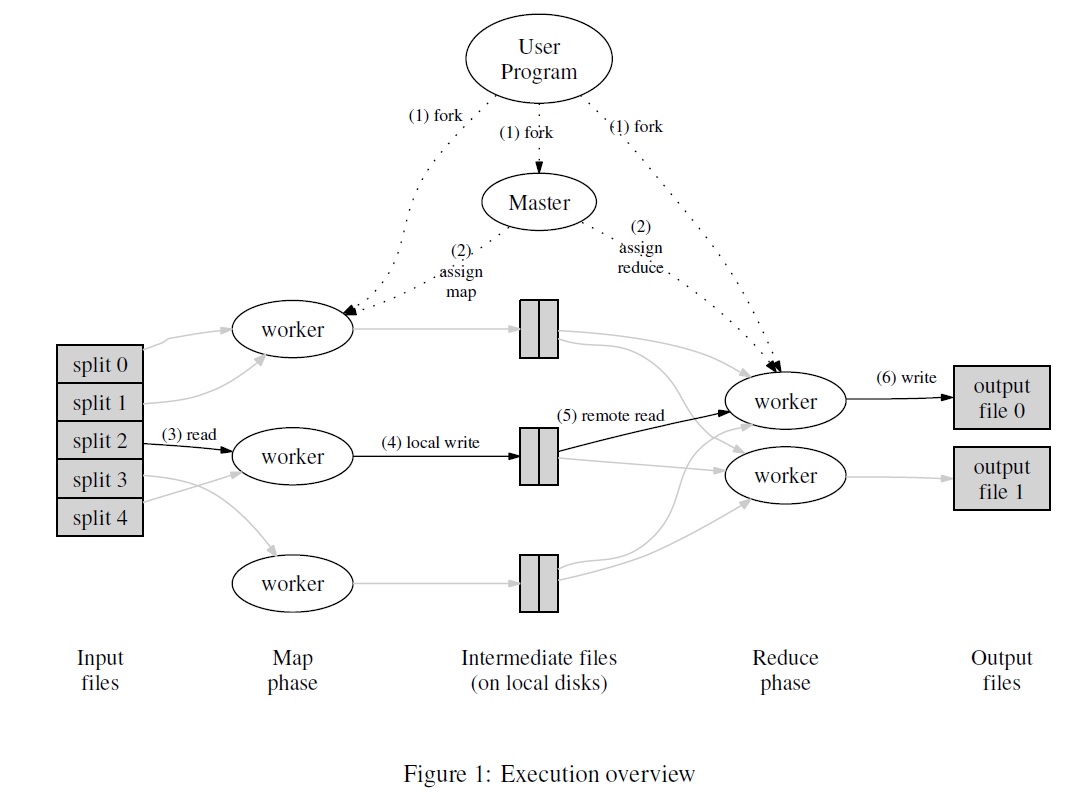
The authors observe that one common cause of long total runtime is “straggler” machines, which takes unusually long amounts of time to complete the last few map or reduce tasks. Stragglers may be caused by ex. bad disk, firmware bugs etc. The proposed solution is to schedule back up executions to other works when close to completion. This way, if one of the workers becomes a straggler, we can rely on the backup workers to complete the task.
Thoughts and Comments
- Would have been nice to evaluate time spend computing vs communication. I am guessing communication would dominate.
- This paper is pretty old (2004). There must have been various improvements on MapReduce since then. Perhaps more fine grained and careful communication controls to optimize utilization.
- I am guessing the disk reads/writes (map worker to reduce worker intermediate result transfer) are the rate limiting step in the overall execution (perhaps the network as well?).
- While MapReduce is probably an innovative idea in distributed computing, this idea cannot be that new in the field of FPGAs right? I find it hard to believe that nobody has ever implemented something similar on the FPGA before 2004. Perhaps the key novelty is applying this idea on a larger scale. Or perhaps this is a “why weren’t we doing that before” moment. I wonder what other FPGA/CGRA ideas can be applied to distributed computing (dataflow? NoC? Synthesis techniques to schedule computation tasks? Routing algorithms to better utilize network bandwidth?).
Sources
[1] J. Dean and S. Ghemawat. MapReduce: Simplified data processing on large clusters. In Proceedings of OSDI, pages 137-149, 2004. research.google.com/archive/mapreduceosdi04.pdf.