Computer Architecture: A Quantitative Approach, Chapter 2 Memory Hierarchy Design
26 Jun 2021
Ten Advanced Optimizations of Cache Performance
1. Using smaller and simpler L1 cache to reduce hit time and power
The critical timing path of a cache hit is 1) find the set with the index 2) compare tag within the set 3) set the mux to select the correct data. Note that the virtual -> physical translation is overlapped with 1). These three steps must occur sequentially, as each step requires results from the previous step. Lower set associativity usually reduces power and hit time, because we access less cache lines in 2). Similarly, larger total cache capacity increases power during step 1).
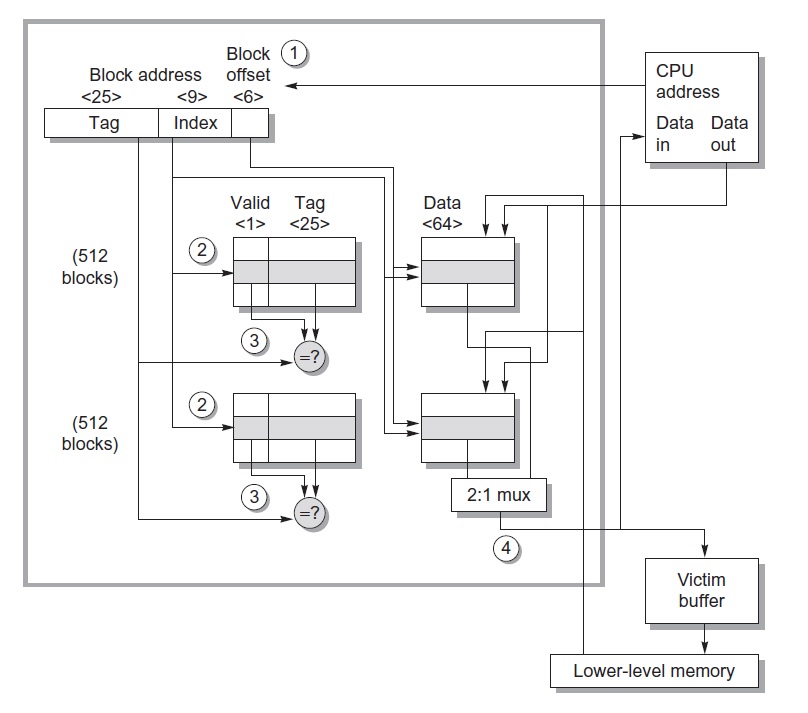
Figure 1: Example cache organization (Opteron). Two way set associative [1].
2. Way prediction to reduce hit time
Way == block within a set. We add block predictor bits to each block in the cache. We then uses these bits to predict which way the next cache access is going to request. Thus, we can perfrom 1) and 2) in parallel, setting the mux to select the predicted way.
3. Pipelining and multibanked caches to increase bandwidth
Pipelining L1 enables faster clock but higher latency. Today’s L1 caches all use some pipelining. To allow multiple data accesses per clock (required for superscalar), we can divide the cache into independent banks, each supporting an independent access. Banking works the best when there is no bank conflict. Sequential interleaving is a simple mapping that aims to address this issue. Ex. for 4 banks, bank 0 contains blocks with address MOD 4 == 0. Banking is also used in L2 caches to support more than one outstanding L1 misses.
4. Non-blocking cache to increase bandwidth
During a miss, do not stall and allow the cache to continue supply proceeding hits. Furthermore, we can overlap multiple misses. To support multiple misses, the L2 cache must be able to service multiple misses. This is essentially cache’s out of order execution. In terms of implementation, we should consider how to arbitrate contentions (ex. two misses are returned at the same time) and track outstanding misses (which instruction caused which miss).
5. Critical word first and early restart to reduce miss penalty
Observation: processor usually needs just one word of the block. Two strategies. Critical word first: request the word in need first, return it to the processor, let the processor resume execution while filling in the rest of the block. Early restart: fetch the words of the block in normal order, but as soon as the desired word arrives, send to processor and resume execution.
6. Write merging
We can merge multiple writes into the same write buffer entry, as shown in Figure 2. This may be beneficial because multiword DRAM writes are faster than individual one word writes. Write merging can also reduce stall time because it reduces the number of entries in the write buffer.
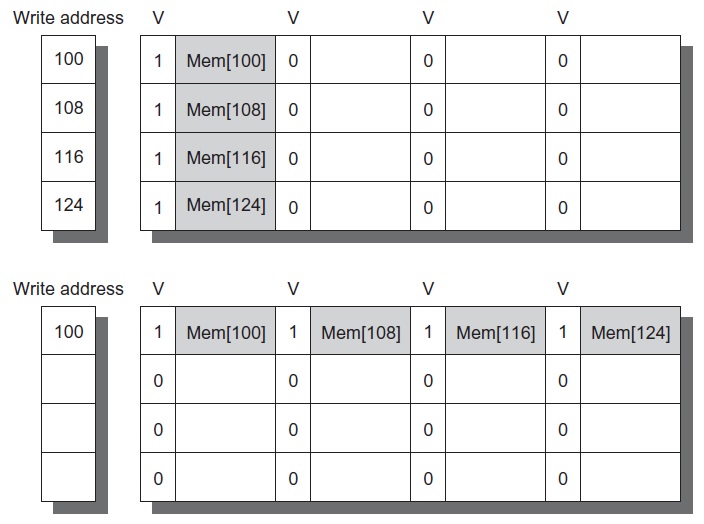
Figure 2: Write merging example [1].
7. Compiler optimizations
Compiler techniques to improve memory performance through locality. These are the high performance computing techniques such as changing the order of loops, dividing memory accesses into blocks to make sure they fit in the cache etc. Book only talks about two techniques. I am sure there are many many more out there.
8. Hardware prefetchimg
Prefetch items before the processor requests them. Can be applied to both data and instructions. The prefetched items can be placed in the cache or an external buffer. Ex. fetch two blocks for every miss: requested block and the one after it. However, if the prefetching requests intefere with demand misses, performance may degrade.
9. Compiler controller prefetching
Relies on complier to insert prefetching instructions. Two types: register prefetch, which load data into register; cache prefetch, into cache but not register. In addition, the prefetches can be faulting or non-faulting. Faulting means the prefetch instruction will cause an exception for virtual address faults or protection violations. Non-faulting raises no exception but simply turn the prefetch instruction into no-op. It makes more sense for prefetching to be semantically invisible, meaning that it should only affect the performance and not the functional behavior. Thus, cache prefetch and non-faulting are more common.
10. Using HBM as additional level of cache
Figure 3 summarizes the above ten optimizations.
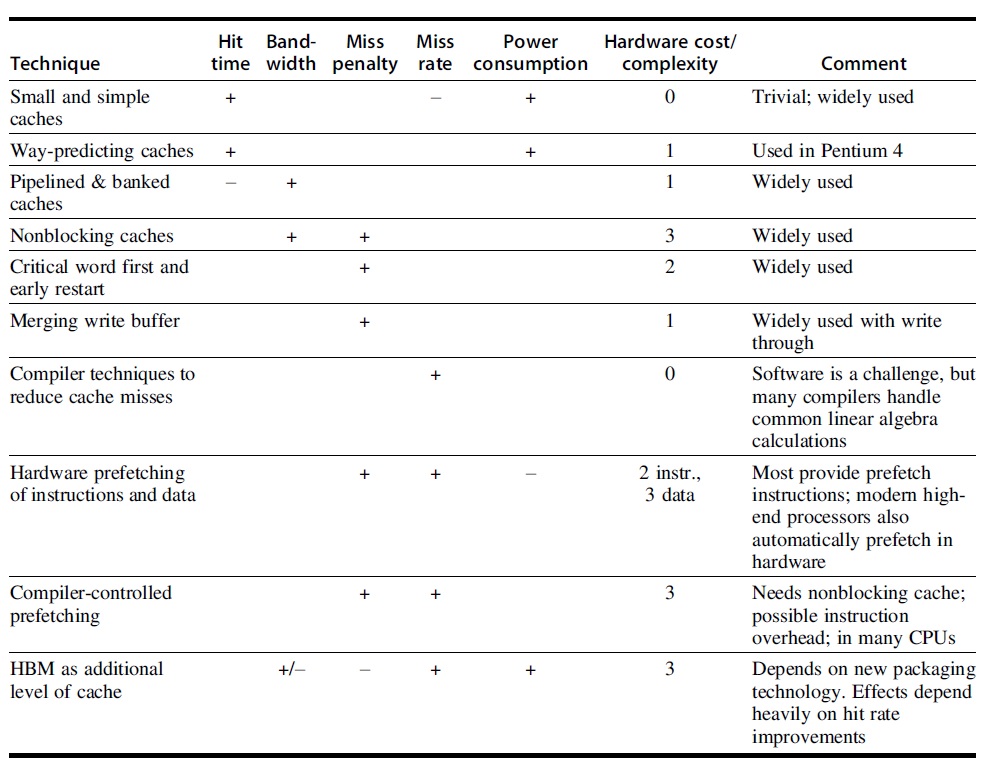
Figure 3: Ten advanced cache optimization summary [1].
Virtual Memory and Virtual Machines
To-do…
Questions
- Hmm, so cache banking allows independent accesses. I don’t think this is the case for DRAM banking?
Sources
[1] J. L. Hennessy and D. A. Patterson, Computer Architecture: Quantitative Approach, Sixth. Cambridge, MA: Morgan Kaufmann, 2019.
[2] Arvind, Modern Virtual Memory Systems. 2005, [Online]. Available: https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-823-computer-system-architecture-fall-2005/lecture-notes/l10_vrtl_mem.pdf