Computer Architecture: A Quantitative Approach, Appendix B Memory Hiearachy Review
24 Jun 2021
Oh boy do I need a refresher on caches and memory. I guess its only natural since I have not used it since the undergrad computer architecture course.
Cache Basics
Caches operate in block (or line) granularity. A block contains multiple words, aimed to exploit spatial locality.
Block placement: where should blocks be placed in the cache? Three basic options: fully associate, direct mapped, and set associative. A set is a group of continuous blocks in the cache. Figure 1 is a pretty good illustration.
- Set associative places blocks in a certain set, and this block can be placed anywhere within that set. A block will be placed in set number = (blk addr) MOD (number of sets in the cache). m-way set associative means each set contains m blocks.
- Fully associative cache contains only one set, so blocks can be placed anywhere.
- Direct mapped cache has set size of 1, so a block is always placed into the same location.
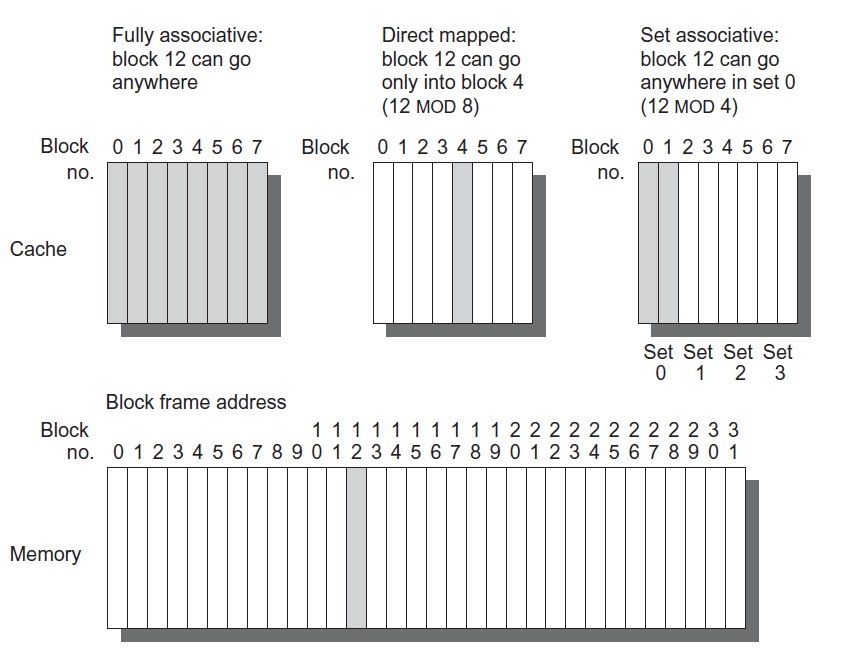
Figure 1: Cache organization illustration [1].
Block identification: how can we find a block in the cache?
- Figure 2 shows how a processor address is broken down. First, we divide between the block address and block offset. The block addr indicates which block this byte belongs to (assuming system is byte-addressable), and the block offset indicates where to find this byte within the block. The block offset is not used by the cache since the cache operates in blocks.
- The block address is further divided into tag and index. The index selects which set the block belongs to (recall MOD), and the tag is used to check if we have a hit in the set. For example, in Figure 1, our block address is 12, or 0b1100. In a 4-way set associative cache, the two LSB bits, 0b00, indicates that block 12 should be placed in set 0. However, blocks 0b0000, 0b0100, and 0b1000 can also be placed in set 0. So the two MSB bits, 0b11, is used to check if a cache hit occurs.
- If we increase associativity, we have less sets but more blocks within a set, so we would need more tag bits and less index bits. Thus, in a fully associative cache, we don’t need any index bits, since there is only one set. However, for direct mapped caches, we still need both the index and tag fields, because we still have multiple blocks per set (ex. in Figure 2, both 0b1100 and 0b0100 map to block 4) and we need the tag bit to differentiate between them. (Unless if we have the same number of blocks in the cache as blocks in the memory, then we don’t need the tag since we have one to one mapping. This is of course not realistic.)

Figure 2: Cache address breakdown [1].
Block replacement: which block should we evict on a miss? Three primary strategies: random, least recently used, fifo.
- Random: evict a random block in the cache.
- LRU: evict the block that has been unused the longest. The hope is to exploit temporal locality.
- FIFO: evict the oldest block.
- Note that we do not need to make a decision in direct mapped caches, since each set only contains one block. The only option is to evict that block.
Write strategy: what happens on a write? Two basic options: write through and write back.
- Write through: the new data is written to both the cache block and the block in DRAM.
- Write back: new data only written to cache block. Dirty data will be flushed to DRAM when it is evicted. Two basic options on a write miss (write miss policy): write allocate and no write allocate.
- Write allocate: first bring the missing block into cache, then modify it.
- No write allocate: do not allocate the missing block in cache. Only change the DRAM. Both write miss policies can be used with write through or write back. But write back typically go together with write allocate.
Six Basic Cache Optimizations
The average memory access time = hit_time + miss_rate * miss_penalty. Thus, to improve cache performance, we improve each of the three variables: reducing miss rate, reducing miss penalty, and reducing hit time.
To understand misses better, recall the 3 Cs:
- Compulsory miss (or cold-start, first-reference miss): the very first access to cache has to be a miss.
- Capacity miss: cache is not large enough to contain all blocks.
- Conflict miss: for set associative or direct mapped, conflict miss occurs when a set cannot fit anymore blocks. This is different from capacity miss because with a conflict miss, the entire cache might not be full (even though the particular set is full).
- (Coherent miss. Not discussed here) The authors note that the 3 Cs is a simple model and has many limits, such as not accounting the replacement policy.
The six basic optimizations are:
- Larger block size to reduce miss rate. Pros: lower miss rate due to higher spatial locality. Cons: increased miss penalty and conflict misses due to increased block size.
- Larger caches to reduce miss rate. Pros: less capacity miss. Cons: longer hit time and higher cost and power.
- Higher associativity to reduce miss rate. Two observations from data. 1) Eight-way set associative is practically as effective as fully associative in reducing cache misses (for a particular cache size). 2) 2:1 cache rule of thumb, where a direct-mapped cache of size N has about the same miss rate as a two-way set associative cache of size N/2.
- Multilevel caches to reduce miss penalty. One thing to consider is whether L1 data should be also in L2, which is multilevel inclusion. On the other hand, we may want multilevel exclusion for small L2 caches.
- Give priority to read misses over writes to reduce miss penalty. With write buffers, we need to be mindful of read after write data dependencies. When a write is in the write buffer, a following and dependent read can check the contents of the write buffer on a read miss and does not need to wait for the entire buffer. to finish writing.
- Avoiding Address Translation During Indexing of the Cache to Reduce Hit Time.
- Since processors use virtual addresses and DRAM uses physical addresses, the virtual -> physical conversion needs to happen somewhere. We could make the cache operate entirely on virtual addresses. This means that on a cache hit, no virtual -> physical translation is needed.
- Although pure virtual caches do not require address translations, the cache must be flushed on a process context switch (since each process has their own virtual addresses). It also suffers from aliasing, where a program may have multiple virtual addresses mapped to the same physical address (ex. mmaping the same file twice to different pointers). The cache will then contain two copies of the same data, causing coherency issues. The third drawback is protection. Page-level protection is offered during the virtual -> physical translation. If the cache is before this translation, one process may access another process’ protected data.
- We should distinguish between two parts of the address: index (find the set) and tag (compare addresses within the set).
- Recall that the major drawback for physical cache is its hit latency. If we can somehow hide this translation latency, then we can use a physical cache to avoid the above virtual cache drawbacks. One solution is virtually index physically tagged cache. In this scheme, we use a part of the page offset, which is the same for virtual and physical (thus do not require translation), as the cache index. While we are searching the cache set with this index, we translate the virtual page number (using the TLB) to a physical page number. We then use this physical page number as the tag to find the cache block within the set. An example is shown in Figure 6.
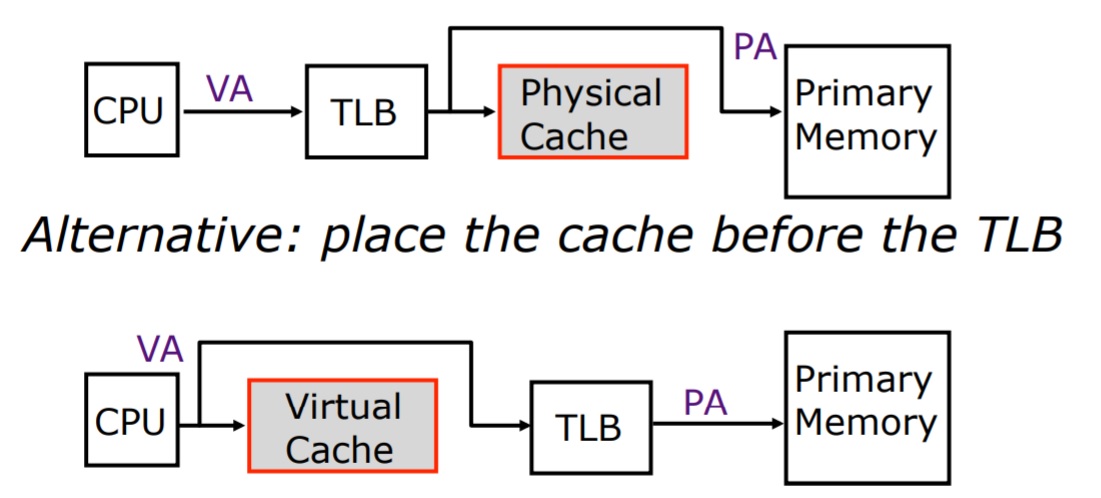
Figure 3: Virtual cache vs physical cache (page table not shown) [2].
Takeaway: many of these optimizations improve one aspect at the expense of another.
Virtual Memory
All processes are assign their own virtual memory address space and page table. When a process request memory access, the OS must translate the virtual address into the physical address. The virtual address and physical address share the same page offset. Only the page number needs to be translated from virtual to physical (since virtual pages are mapped to physical pages).
Page placement: pages can be placed anywhere in memory because the miss penalty to disk is too high. This is analogous to a fully associative cache.
Page identification (how to find a page in main memory): look up the page table, which maps virtual page number to its physical address, as shown in Figure 5. A translation lookaside buffer (TLB) is used as a page table cache to speed up this translation.
Page replacement: all most all OS uses LRU. This is usually implemented with a use-bit, which is set whenever the page is used. The OS periodically clears the use bits.
Write strategy: since disks are very slow, existing designs always use write-back and never write-through.
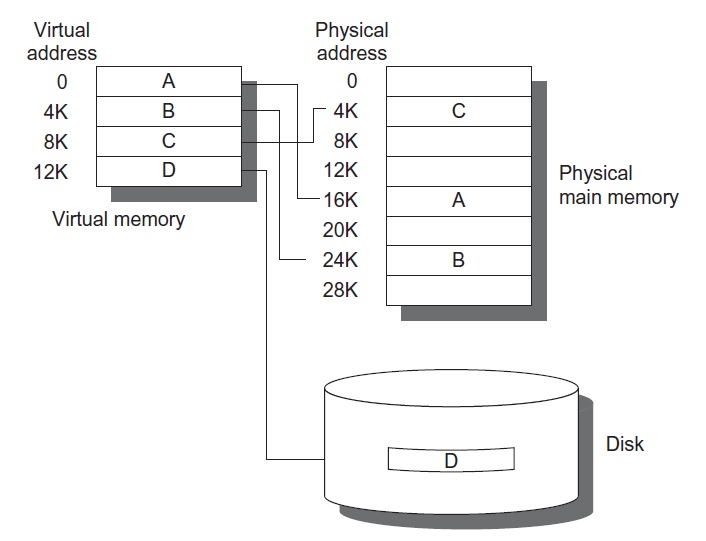
Figure 4: Virtual memory. The program consists of four pages, each 4KB [1].
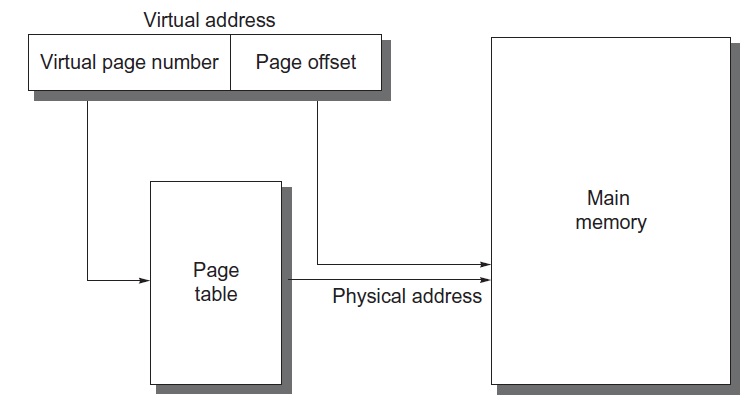
Figure 5: Virtual address mapping [1].
An example that includes virtual memory and caches is shown in Figure 6. First, we try to find the data in L1 cache by performing virtual -> physical page number translation and virtual cache index look up in parallel. To perform the translation, the virtual page number is divided in to tag and index for the TLB, just like with a cache. If a hit occurs in the L1 cache, we are done. If not, we look up the data in L2. Note that L2 operates with physical address only.
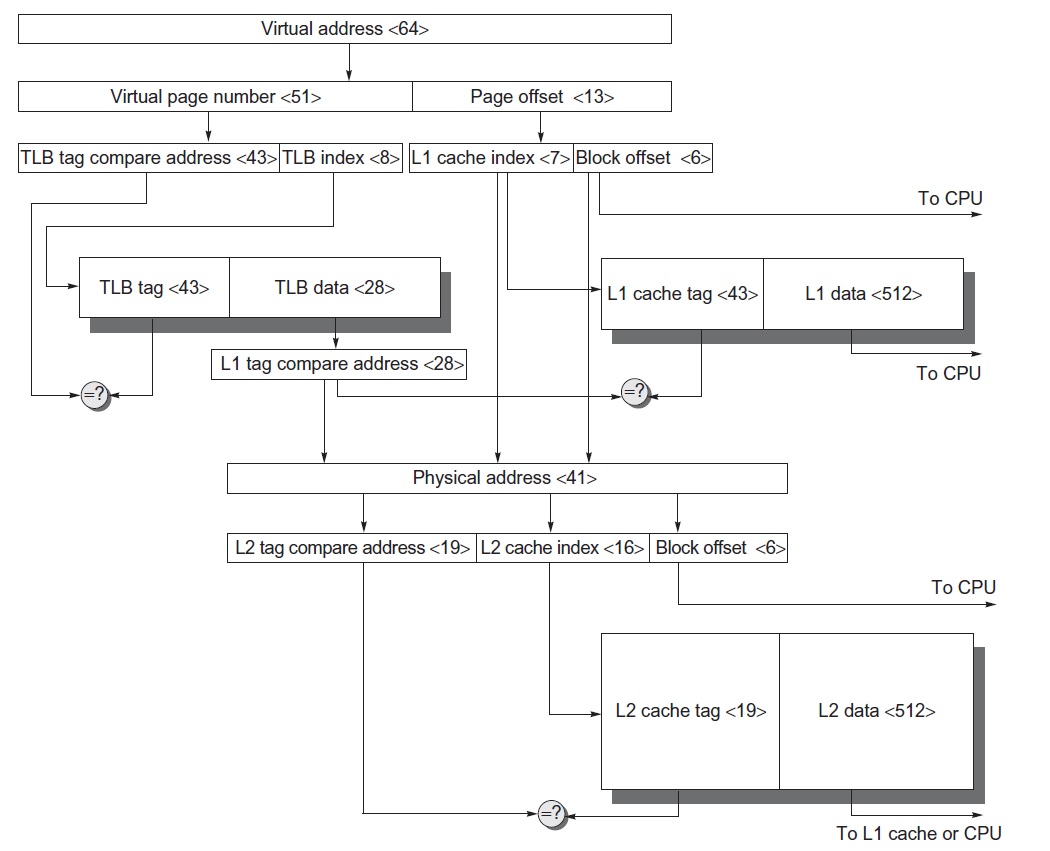
Figure 6: Virtual memory and cache example [1].
Thoughts and Comments
- Many design decisions here are made based on existing memory technology and their characteristics. Ex. DRAM writes are never write-through because disk is too slow. I wonder if they would change with new memory technologies (ex. SSD, NVM, HBM)
Sources
[1] J. L. Hennessy and D. A. Patterson, Computer Architecture: Quantitative Approach, Sixth. Cambridge, MA: Morgan Kaufmann, 2019.
[2] Arvind, Modern Virtual Memory Systems. 2005, [Online]. Available: https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-823-computer-system-architecture-fall-2005/lecture-notes/l10_vrtl_mem.pdf