#13 ThyNVM: Enabling Software-Transparent Crash Consistency in Persistent Memory Systems
21 Jun 2021
| Link | https://ieeexplore.ieee.org/document/7856636 |
| Year | MICRO 2015 |
Details
Motivation
To program persistent memory, most prior works require special interfaces/libraries (ex. PMDK) to allocate and manage the NVM. This paper argues that this approach puts too much burden on the program. In addition, most of these prior works use either logging or copy-on-write (CoW) to implement crash consistency. Logging implementations use logs, persisted separately from the working memory, to record the new or old values of write operations. After a crash, the system retrieves the log and redo/undo actions to put the system in a consistent state. The authors argue that logging can consume large NVM capacity than the original data (each log entry requires both data and metadata) and log replay increases recovery time. Shadow paging is one implementation of CoW. In shadow paging, when a page needs to be modified, the system allocates a separate shadow page and apply the changes there. After a crash, the system’s original state is unaffected since all changes were made to the shadow page. To commit, the system updates all references to point to the shadow page. The authors argue that CoW’s copy operations are costly and NVM bandwidth is wasted when updates are sparse. ThyNVM uses checkpointing to ensure crash consistency. The system periodically takes consistent snapshots of the volatile data and store the snapshots in NVM.
The working copy of data is the copy of data that is being actively updated by the processor. ThyNVM aims to address two drawbacks of checkpointing: 1) checkpointing latency 2) metadata overhead to track where the working copy and checkpoint are. The paper observes tradeoffs between 1) and 2) in two axes: checkpointing granularity and location of working copy.
First, the checkpoint granularity, which is the granularity at which we keep track of the working/checkpoint data, determines the metadata overhead. At a large granularity (ex. page), the metadata required is small compared to at a smaller granularity (ex. cache block). I think makes sense since there are more cache blocks in total, so we need more bits to represent them. Not sure exactly how the metadata keep track of data locations. Let’s keep reading. Second, the working copy’s location determines the checkpoint latency, which is the latency of checkpointing the working copy. If the working copy resides in DRAM, the system must write the working data back to NVM during checkpointing, resulting in long latency. On the other hand, we can place the working copy in NVM to avoid long checkpoint latencies. Check the Block Remapping section for details.
Figure 1 summarizes the tradeoff space for the two axes. Actually, there is a third axis: remapping speed. This only applies to storing the working copy on the NVM. Large granularity means slow remapping. This makes (4) inefficient. ThyNVM aim to utilize schemes (2) and (3).
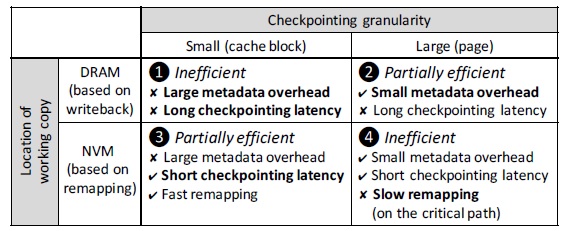
Figure 1: ThyNVM tradeoff space [1].
Design
Checkpointing Model
ThyNVM adopts the epoch checkpointing model, which divides the program execution time into time periods called epochs. Each epoch has an execution and checkpointing phase. One of ThyNVM’s key ideas is to pipeline successive epochs, as shown in Figure 2 (b). This pipelined scheme requires ThyNVM to maintain three versions of data across successive epochs: the active working copy, the last checkpoint, and the penultimate (aka. 2nd last) checkpoint. (I think epoch 1’s working copy also needs to be kept at time t. In DRAM mode, I think epoch 1’s still need its working copy while checkpointing, since the dirty pages are still being flushed to NVM.) The first reason is because since epoch 0’s checkpointing and epoch 1’s execution overlap, they may access the same data and mess things up. Furthermore, if the system crashes at time t as shown in Figure 2, both epoch 1 and 2 are gg. In this case, ThyNVM needs to recover to epoch 0’s checkpoint.
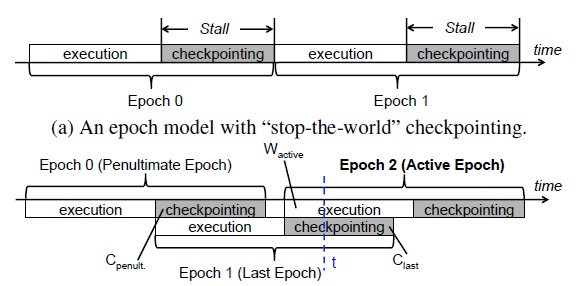
Figure 2: ThyNVM epoch model [1].
Block Remapping (working copy in NVM + cache block granularity)
This scheme enables applications to update the working copy directly during execution. So how to we store the checkpointed (ie. older versions) of the data? During the checkpointing phase, the current working copy becomes the latest checkpoint. ThyNVM does this by persisting only the metadata needed to locate this latest checkpoint. Then, in the next execution phase, since we cannot overwrite the last checkpoint, ThyNVM uses the block translation table (BTT) to remap the working copy to another address. The BTT maps data blocks to the addresses of their working copy. For example, let us say that in the latest checkpoint, we have A=1 at 0x10. During the execution phase, the processor issues a store A=2. We add an entry in the BTT to obtain an address, let us say 0x40, to store the working copy of A. The BTT’s new entry is then (the block that contains A, 0x40). We then copy cache block A to 0x40 and store A=2 there. Note that if we use page granularity here, we would need to copy more data (the page that contains A). The authors note that this strategy should be applied to data updates exhibiting low spatial locality since the granularity is small.
Page Writeback (working copy in DRAM + page granularity)
This scheme caches hot pages in DRAM during execution and writes back dirty pages to NVM during checkpoint. As discussed in the epoch checkpointing section, since we need to keep data for three epochs, we cannot overwrite the existing checkpoint during the checkpointing phase. The page translation table (PTT) redirects dirty pages to different NVM addresses. The authors note that in this scheme, the next epoch cannot modify DRAM pages before the previous epoch finishes checkpointing. Wait, then how do we overlap epochs? See next section.
Coordinating the Two Schemes
ThyNVM dynamically adapts the checkpoint scheme at a page granularity (each page has its own scheme). The scheme is chosen at the start of each epoch based on the access spatial locality and write intensity. (This part is somewhat confusing for me) As described at the end of the previous section, page writeback does not allow subsequent epochs to update the DRAM while the current epoch is checkpointing. I think this means we cannot overlap a DRAM mode epoch with a following DRAM mode epoch. The proposed solution is to switch to block remapping (NVM mode) for the next epoch, which does not modify the DRAM. Thus, while epoch x is flushing its dirty pages from DRAM to NVM, epoch x+1 can start executing and writing to the NVM in parallel (in different addresses of course. Recall that Clast and Wactive are kept separate). While these two epochs both require writing to the NVM, I think the authors are implying that the NVM has enough bandwidth to handle both. A NVM mode epoch can follow another NVM mode epoch no problem, since they write to different areas in the NVM. So in summary, I think ThyNVM does not allow a DRAM mode epoch followed by another DRAM mode epoch, as this will cause the two epochs to checkpoint and execute sequentially. The three other combinations, DRAM->NVM, NVM->NVM, NVM->DRAM, are allowed.
Thoughts and Comments
- I am confused about ThyNVM’s use case. The paper claims that instead of using libraries such as PMDK to explicitly partition
data between volatile and persistent memory, ThyNVM implicitly manages persistent data. I thought most of NVM’s benefits are enabled
by the user’s ability to intelligently partition data. For example, if an application requires a larger memory capacity, we can move
less frequently accessed objects to the NVM to effectively expand the memory capacity. How can ThyNVM achieve this if the
programmer cannot explicitly manage persistent data?
- ThyNVM enables the programmer to “magically” persist all of their original volatile data. In other words, I think ThyNVM only offers persistence. This could be beneficial for ex. applications that require faster reboot time, but I do not know if ThyNVM can utilize other benefits on NVM. Remember that persistence is only one of NVM’s properties. For example, people have been manually porting Redis to NVM using PMDK. Sure, we could run the original Redis as is on an NVM platform with ThyNVM. The NVM is being utilized and all previously volatile data are now persistent and crash consistent, but is this what we want? I don’t think so, because we want benefits beyond just persistency.
- In summary, I think ThyNVM is useful for applications that only wish to obtain persistency and crash consistency.
- The idea of software-transparency is very interesting. Zero programmer effort is very appealing, but I believe ThyNVM is too inflexible for many applications. With ThyNVM, an application either persists all of its data or none at all. This cannot be good for the overall performance.
Questions
- How are transactions implemented without logs?
- The paper seems to suggest that people use transactions in order to achieve crash consistency. Since ThyNVM already provides crash consistency, there is no need to implement transactions. A quick search shows that this is indeed true, as ThyNVM seems to cover the A, C, and D of ACID. But what about isolation? Transaction achieves isolation between programs accessing data concurrently. Can ThyNVM provide isolation? In fact, this paper does not talk much (if at all) about scaling to multicores.
- Is the NVM just used for checkpointing?
- Nope. Also used as working memory in block remap mode.
- How is checkpointing different from undo logging?
- I agree they have some similarities conceptually. See Motivation section for difference.
- How does ThyNVM ensure the checkpoints themselves are consistent?
- Recall that each epoch contains execution and checkpointing stage. The snapshot is taken at the end of the execution stage, so ThyNVM needs to make sure the memory is consistency at this point in time. This should be easy since ThyNVM controls when to end the execution stage (although it does not control when the execution stage starts).
- How can I access non-volatile data if there is no explicit interface to do so?
- I believe that answer is you don’t, at least not directly. After the system crashes, ThyNVM will restore whatever data you had in the working memory and the execution state. So I think from the programmer’s perspective, you can just pretend that the crash never happened, since everything is taken care of in the hardware. Thus, there is no need to explicitly access non- volatile data.
Sources
[1] J. Ren, J. Zhao, S. Khan, J. Choi, Y. Wu, and O. Mutlu, “Thynvm: Enabling software-transparent crash consistency in persistent memory systems,” MICRO, 2015.