#9 An Empirical Guide to the Behavior and Use of Scalable Persistent Memory
18 Jun 2021
| Link | https://arxiv.org/abs/1908.03583 |
| Year | FAST 2020 |
Big Ideas
- PM performance is more dependent on access size, type, pattern, and concurrency than DRAM.
- PM internal:
- Physical media access size is 256B. On-DIMM controller performs write combining, otherwise read-modify-write (write amp).
Details
Background
On the Intel Cascade Lake platform, each processor contains one or two processor dies (not too sure how this works. Recall that a die is simply a piece of silicon). As shown in Figure 1 (a), each processor die contains two integrated memory controllers (iMC), and each iMC supports three memory channels. In total, each processor die can connect up to six 3DXP DIMMs. The iMC maintains read and write queues (RPQ and WPQ) for each of the DIMMs, as shown in Figure 2 (b). Recall that in ADR the WPQ is included in the persistence domain. The iMC talks with the NVMs via DDR-T in cache-line granularity (65B). This interface is physically the same as the DDR4 but uses a different protocol (I think this is DDR-T).
An NVM Access
A NVM accesses can be broken down into the following steps:
- first arrives at the on-DIMM controller (XPController) that coordinates access to the storage media.
- The controller performs internal address translation for wear-leveling. The address indirection table (AIT) is used for this translation.
- The physical media’s access granularity is 256B (XPLine). The XPController translates smaller requests into 256B accesses. This causes write amplification (an undesirable phenomenon where the actual amount of data written to the media is larger than the logical amount). The XPController has a small write-combining buffer (XPBuffer) to perform write merging (64B to 256B internal writes). If the write is smaller than 256B, the write operation becomes the more expensive read-modify-write (if 256B write, just overwrite everything).
Seems like the XPBuffer is also used as a cache. E.g. a 64B read will bring the entire 256B line into the XPBuffer, so that subsequent reads within the 256B line can be directly served from the XPBuffer.
The NVDIMMs can also be interleaved across channels and DIMMs, as shown in Figure 1 (c). I think this means partitioning the address space in an interleaved fashion for better performance. The paper notes that the only interleave size supported by their platform is 4KB, which ensures a single page falls into a single DIMM. If we have 6 DIMMs and access a continuous memory larger than 24KB, we will access all DIMMs.
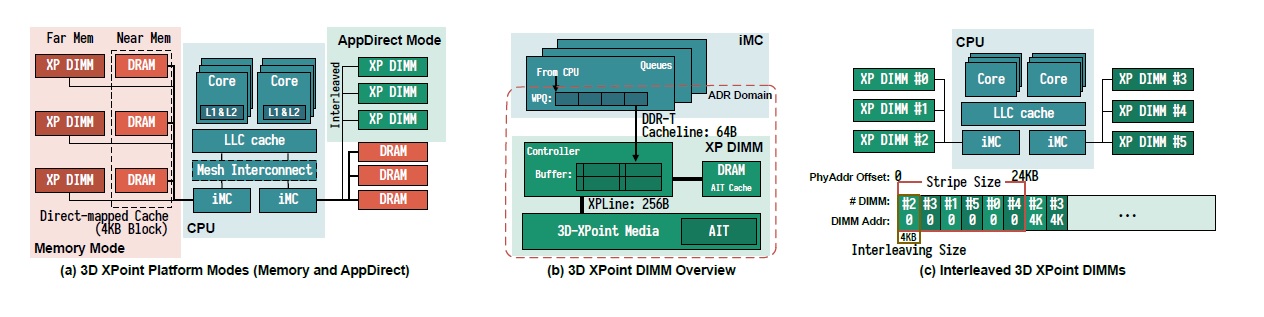
Figure 1: Overview of Intel 3D XPoint NVMDIMM [1].
A Quick Word on App Direct Mode
Since the caches can change PM store ordering (making recovery complicated). To enforce PM write ordering (to the physical media), programmers can use clflush and clflushopt to flush cache line to PM. clwb writes the line to PM but does not evict the entry from the cache. ntstore allows the write to bypass the caches.
Performance Characterization
The authors first develop a microbenchmark toolkit called LATTester to replace prior benchmarks designed for DRAM or disk.
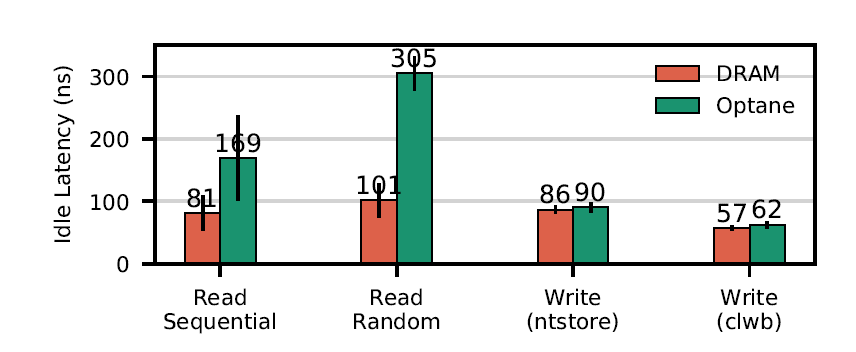
Typical latency (latency seen by the software, not the device) :
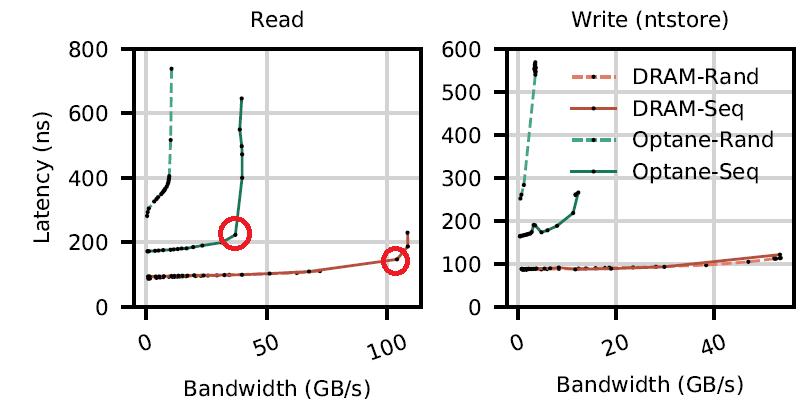
Key numbers to remember: 300ns random read, 2x better if sequential. 100ns for writes.
- NVM read latency is 2-3x higher than DRAM. The authors believe this is due to NVM’s longer media latency.
- NVM is more pattern dependent than DRAM, having a higher random vs. sequential gap (80% vs 20%). The authors believe this is due to the XPBuffer, but does not go into more details (see Question 2).
8B accesses
Tail latency:
Summary: tail latencies are rare but 2 orders of magnitude slower.
- Tail latency is the worst-case latency in comparison with the average latency. They can be considered outliers. Tail latency is expressed in percentiles. Long tail latencies correspond to high percentiles.
- The number of outliers increase when acceses are concentrated in a small “hot spot”. Thus, the authors suspect that this is because of wear-leveling remapping.
- The tail latency spikes are rare (0.006%) but has 2 orders of magnitude higher latency.
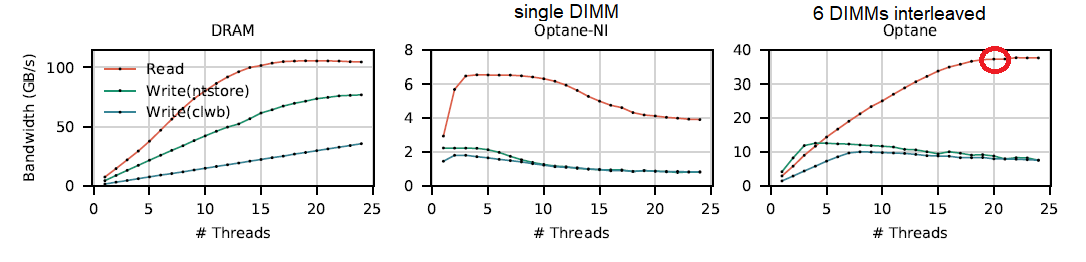
Bandwidth:
Summary:
- Single DIMM read BW is ~6GB/s, write 2GB/s
- Interleave improves BW almost linearly and helps scaling : single DIMM r/w scales upto 4 threads only, 6 interleaved to >20 threads
- PM reads scale better than writes with thread count. Why? Most likely due to the nature of the device: the write BW is already saturated.
-
Random accesses smaller than 256B has poor BW. Interestingly, for interleaved (6 DIMMs), random accesses close to 4kB also has low performance (20% drop). Why? See Best Practice section 3.
- In relation to thread count,
- DRAM bandwidth is both significantly higher and scales more predictably than NVM.
- NVM bandwidth (no interleave) decreases after four threads, where as DRAM bandwidth saturates at high thread counts. Interleave NVM improves the peak to twelve threads.
- Read bandwidth is higher for both NVM (2.9x) and DRAM (1.3x)
Sequential 256B accesses:
- In relation to access size,
- NVM random access under 256B has poor BW (XPLine size).
Random accesses:
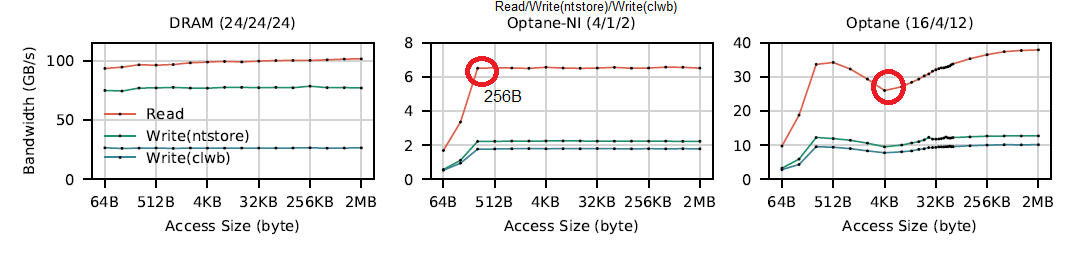
Latency under load: When max BW is reached, latency degrades significantly due to queuing effect (likely in the WPQ). This is also true for DRAM.
Best Practices for PM (aka. so what do these mean for the application?)
- Avoid random accesses smaller than < 256 B.
- Small random reads are obvious not efficient since they do not take advantage of the XPBuffer cache.
- Small random writes are even worse since writes < 256B causes write amp + read-modify-write and write BW is scarce.
- But, if the small writes can be somewhat combined into 256B writes, performance is not so bad. Authors show that the XPBuffer has 64 lines, or 256B*64=16KB in size (per DIMM).
- The paper suggests to “avoid small stores, but if that is not possible, limit the working set to 16 KB.” Why does working set < 16 KB help with small accesses? The authors seem to be saying that the internal XPBuffer can reorder writes. So even if the writes are small, the XPBuffer can wait (buffer) for more writes within the 256B line.
- Use non-temporal stores when possible for large transfers, and control of cache evictions.
- Non-temporal store, or
ntstore, is an alternative toclwborclflushthat bypasses the cache hierarchy entirely. Note that we still need asfenceafter it. - Experiment results show that non-temporal stores have higher bw than cache line flushes for accesses over 256B. The authors suspect that this is because using the cache requires the CPU to load the cache line from NVM first, thus using up the NVM’s bandwidth.
- Non-temporal store, or
- Limit the number of concurrent threads accessing a 3D XPoint DIMM.
- The paper identifies two factors that limit NVM’s poor concurrent performance: 1) more threads means more XPBuffer contention and evictions 2) iMC queue contention. The authors suspect that if the WPQ injection rate is much higher than the service rate, the queue will block.
- Avoid NUMA accesses (especially read-modify-write sequences).
- The authors note that NUMA effects for NVM is much larger than DRAM.
- I do not know how NUMA works yet. I should definitely learn this.
Thoughts and Comments
- Many observations from this paper can only be educated guesses (even reverse engineered) because the hardware is close source. I think this really limits and slows down research in the area. I feel more motivated by open source hardware now.
- “As the 3D XPoint DIMM is both persistent and byte-addressable, it can fill the role of either a main memory device (i.e., replacing DRAM) or a persistent device (i.e., replacing disk). In this paper, we focus on the persistent usage…” This seems to imply that replacing DRAM == volatile usage and replacing disk == persistent usage. I don’t think this is always true. Prior works (ex. Redis for pmem) have used NVM persistently to replace DRAM (and potentially disk as well).
- Since prior emulator and real NVM results differ significantly, it might be valuable to re-evaluated prior work and validate conventional wisdom. Now that Intel released its second generation NVM, new features such as eADR will likely challenge prior assumptions and results even further.
Questions
- “It is important to note that all updates that reach the XPBuffer are already persistent since XPBuffer resides within the ADR. Consequently, the NVDIMM can buffer and merge updates regardless of ordering requirements that the program specifies with memory fences.” Why does persistence mean the NVM can ignore ordering? Ex. two persists to the same location?
- Why does NVM have more pattern dependency than DRAM (larger random vs. sequential latency gap)? The authors believe this is caused
by the XPBuffer, but does not elaborate further.
- Recall that the XPBuffer performs write combinig from 64B to 256B internal writes. It makes sense for random writes to be slower, but the experiments show read latency. How does XPBuffer affect read latency?
- Ah, this is because the XPBuffer is used as a cache. The first read brings an entire XPLine into the XPBuffer and the following reads can read from the buffer.
- But why does DRAM not have this problem? Is DRAM’s internal access size much smaller and thus the penalty for “cache” miss is lower? Seems like the typical DRAM access size (or page size) is 8kB.
- Then I think this is because DRAM has inherently lower “cache” miss penalty, as “…the cost of opening a page of DRAM is much lower than accessing a new page of 3D XPoint.”
Sources
[1] Jian Yang, Juno Kim, Morteza Hoseinzadeh, Joseph Izraelevitz, and Steve Swanson. An empirical guide to the behavior and use of scalable persistent memory. In 18th USENIX Conference on File and Storage Technologies (FAST 20), 2020