#6 AutoPersist: An Easy-To-Use Java NVM Framework Based on Reachability
16 Jun 2021
| Link | https://dl.acm.org/doi/10.1145/3314221.3314608 |
| Year | PLDI 2019 |
Details
This paper presents AutoPersist, a Java NVM programming interface aimed to minimize programmer burden. Existing NVM programming interfaces such as PMDK require programmers to identify and label all persisten objects, such as shown in Figure 1. (As an aside, I don’t believe the code shown in Figure 1 is crash consistent, because there is no SFENCE between the two CLWBs.) The authors argue that this approach is susceptible to correctness bugs and reduced performance, as it is easy for programmers to mislabel the persistent objects. AutoPersist only require user to identify durable root, the entry pointers to persistent data structures. The framework then automatically ensures that all objects reachable from the durable root are automatically stored and updated to the NVM.

Figure 1: Example NVM programming interface [1].
Since the last time I wrote Java code was in first year undergrad, let us do a quick review of Java. Different from languages such as C, Java utilizes Java Virtual Machine (JVM) as its runtime engine to run Java applications. Recall that in general (since a quick search reveals that different people define this term differently), runtime refers to code that provide the environment for programs to run. Thus, Java applications are compiler once run anywhere. In addition, Java is a managed language, meaning that is runs on a virtual environment (source from Internet). We do not have to dig too much into this, as the key thing to note is that Java manages your memories for you via the garbage collector (GC). The GC does this by continuously identifying and eliminating unused memory.
AutoPersist utilizes the Java GC to dynamically track objects and deciding whether they should be persisted or not. An example AutoPersist behavior is shown in Figure 2. In this example, since Nodes C and E are reachable via the durable root, they are moved to NVM from DRAM by AutoPersist.
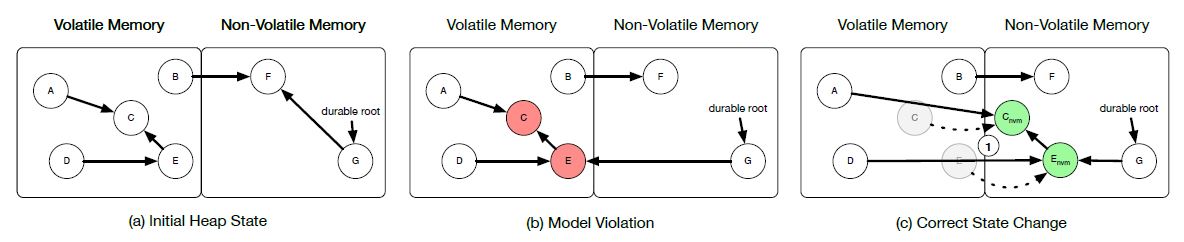
Figure 2: Example AutoPersist behavior [1].
To support failure atomic regions (blocks of code that either happen or don’t), AutoPersist requires programmers to label the start and end of the region. Persists inside failure atomic regions follow epoch persistency, while persists outside follow sequential persistency (I believe PMDK does the same).
Sections 5, 6, and 7 discuss the project’s implementation and optimization details, which I will skip for the moment.
The authors evaluate AutoPersist with two real world applications: key-value store and H2 database. For the key-value store, the paper compares Espresso, a prior work that also targets Java applications, and AutoPersist. The author port the key-value store application, originally written in Java with DRAM in mind, to NVM using both AutoPersist and Espresso. AutoPersist shows significantly reduced number of code. AutoPersist also outperforms Espresso in terms of runtime, because AutoPersist minimizes the number of CLWB calls. For the H2 database, the paper comapres H2’s current implementation, legacy implementation, and AutoPersist. To make the evaluation fail, all three implementations use NVM as the storage device. AutoPersist executes 3% faster than the legacy implementation and 38% faster than the current implementation (yes the legacy version somehow outperforms the current version significantly).
Thoughts and Comments
-
The idea of AutoPersist not only can help programmers to write new NVM programs, but also porting legacy libraries to NVM platforms.
-
I wonder if less programmer burden is always better. I believe this needs to be balanced with performance. This paradigm of programmability vs. performance also shows up in memory consistency/persistency, where the programmers are required to write more code for better performance (ex. relaxed models). So I think zero programmer burden is perhaps realistic, but likely not desirable.
-
The idea of moving objects into persistent memory at runtime seems like extra work. Objects need to be allocated in volatile memory once AND in persisten memory again. I wonder if this can be avoided.
-
The authors mention that “While requiring the programmer to label many objects is both user-intensive and bug-prone, it does match the traditional level of abstraction provided by lower-level languages such as C and C++.” I disagree. I do not think this is a solid reason for not exploring better (programmability, performance etc.) programming interfaces for low level languages. I understand that the authors might have used this statement to motivate their work, but I do not think we should abandon low level languages because “they are low level anyways” (quote mine).
-
AutoPersist’s support for failure atomic regions requires users to label the region’s start and end. This sounds likes what existing programming interfaces (ex. PMDK) are already doing (not saying this is a bad thing). Perhaps AutoPersist can consider using existing failure atomic region implementations for better ex. performance?
-
In the evaluation of the key-value store application, since the original code is a volatile implementation (no NVM), it would have been interesting to see the performance comparison between AutoPersist and volatile version. I think this is important because one of the major use cases of AutoPersist is porting legacy Java applications (that used DRAM) to NVM platforms. When doing this porting, the user will want to know the port’s performance implications (perhaps penalty, since currently NVM is inherently slower than DRAM). That being said, the NVM version of the key-value store offers more capabilities than the volatile version (ex. persistency, crash consistency), so I somewhat understand why the volatile baseline is not used.
-
In the evaluation of the H2 database, the authors point out that H2’s current and legacy implementations persist data using file operation, which operate on blocks. On the other hand, AutoPersist uses the NVM in byte-addressable mode. I am not sure if this is fair.
-
AutoPersist only outperforms H2 database’s legacy storage backend by 3%. This is surprising since the legacy backend was not designed with NVM in mind at all, whereas AutoPersist was. That being said, the major advantaege of AutoPersist is its programmability, which showed significant improvements over existing solutions.
Questions
- Why would we want “All objects reachable from the durable root set must be in NVM”? What observations led to this rule? I think
the motivation was unclear, as the paper just states this design decision.
- I guess it kind of make sense that if one part of a large object structure (ex. linked list) is persistent, we would want rest to be persisten as well..
Sources
[1] Thomas Shull, Jian Huang, and Josep Torrellas. 2019. AutoPersist: an easy-to-use Java NVM framework based on reachability. In Proceedings of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI 2019). Association for Computing Machinery, New York, NY, USA, 316-332. DOI:https://doi.org/10.1145/3314221.3314608
[2] https://www.geeksforgeeks.org/jvm-works-jvm-architecture/
[3] https://www.infoworld.com/article/3272244/what-is-the-jvm-introducing-the-java-virtual-machine.html