#5 Supporting Legacy Libraries on Non-Volatile Memory: A User-Transparent Approach
15 Jun 2021
| Link | https://conferences.computer.org/iscapub/pdfs/ISCA2021-4ghucdBnCWYB7ES2Pe4YdT/333300a443/333300a443.pdf |
| Year | ISCA 2021 |
Summary
Details
This project identifies the problem that porting legacy libraries to run on NVM is a large obstacle for persistent memory to be used in the real world. There have been efforts to rewrite existing libraries for NVM, but they are usually slow, costly, and error prone. To combat this, the paper proposes user-transparent persistent reference that allows users/libraries to reference persistent objects in the same ways as normal objects. This way, we can minimize or even eliminate changes needed to port legacy libraries onto NVM.
Persistent memory are usually organized in pools (ex. PMDK). Since persistent pools are, well, persistent, persistent pointers need to remain valid across applications runs. Modern OSes adopt address space layout randomization (ASLR), which may change the persistent pool’s virtual memory address across execution. Thus, we cannot use the typical “absolute” virtual memory addressing scheme for persistent pointers anymore. An example is shown in Figure 1. The naive scheme does not work if the pmem pool is remapped to a different virtual address range. Thus, PMDK represents presistent pointers with a pool identifier and a pool offset. The pool ID is used to look up the pool’s base virtual address. We can then compute the persistent pointer’s virtual address via base addr + pool offset. As a result, persistent pointers pointers do not work well (if not at all) with existing libraries, which were designed to operate on normal pointers. A code example is shown in Figure 2 left. If p and n are persistent pointers, then the library will not function as expected.
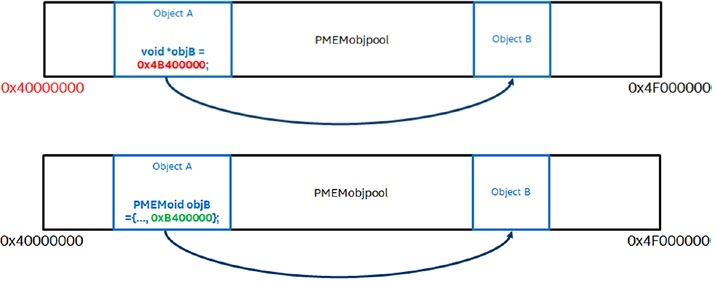
Figure 1: PMDK persistent pointer implemetations. Naive (top) and PMEMoid (bottom) [3].
The paper emphasizes that the solution should not rely on features specific to a particular language. Prior works rely on Java’s garbage collector to perform persist operations, but this is not applicable to lower level languages such as C.
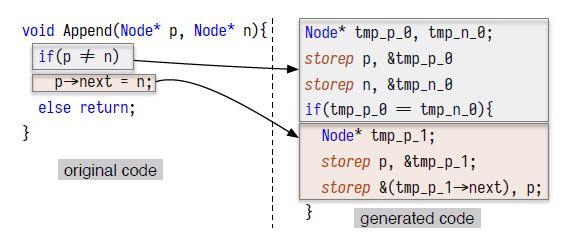
Figure 2: Linked list generated code [1].
The proposed solution is simple (or at least the idea is simple, I think): embed the pointer’s type information (relative or virtual) in the pointer itself. Check the pointer’s type at runtime and perform different actions based on the pointer type. The two pointer representations are shown in Figure 3. Note that virtual addresses can also point to NVM data. See question 1 at the end of this post. Figure 4 shows the pseudo code for the runtime check algorithm. (Maybe these are common naming conventions, but I found the pseudo code confusing. Why are X and Ys? What is the pointer assignment doing with to and p? Why is determineY’s if statement checking on bit 64 of val? I will proceed with my assumptions to the above questions.)
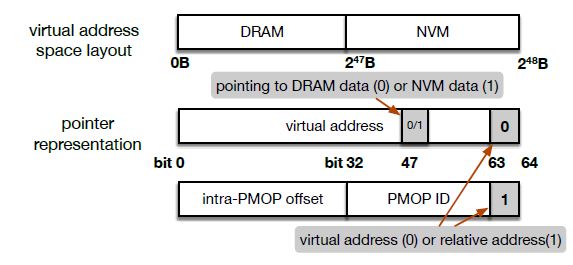
Figure 3: Pointer representations [1].

Figure 4: Runtime checks for pointer type. (I am not sure why the original code uses != and generated code uses ==. Perhaps a mistake?) [1]
With the new pointer representation, we need to update pointer operation definitions as well. For example, two pointers are equal if their translated virtual addresses are the same. The paper demostrates their approach’s soundness by providing new semantics for all C11 pointer operations.
Optimizations
Naively, the proposed method requires dynamically checking the pointer type at every pointer access. This is not cool and results in low performance (shown in Evaluation section). The paper proposes two ways to reduce this overhead: hardware support and compiler transformation.
1) Hardware support. The authors separate the original store instruction into two new instructions: store D (regular store) and storeP (stores a pointer value to a memory location). A new store pointer instruction is required because the pointer may need to be converted before written to memory (depending on the destination memory location). For example, in Figure 2 right, the storeP instruction is used support the pointer comparison operation. Since the tmp variables are on the stack, they must reside in DRAM (thus have virtual address format). The two subsequent storeP instructions convert p and n to virtual address pointers if needed (based on the storeP semantic). The proposed design also adds a storeP function unit into the processor pipeline and various extra components in the memory controller to speed up the storeP instruction execution.
2) Compiler transformation. The idea here is to use static analysis to infer actual pointer types to avoi dynamic checks. However, the compiler cannot determine the types of all pointers. In that case, the compiler inserts runtime checks.
Evaluation
The authors evaluate the proposed designs on Snipersim (since there are hardware changes). The benchmarks used are Boost (C++ library) and a KNN application. The evaluation compares 4 application versions: HW (hardware based user transparent persistent references), SW (compiler based), explicit (aka. rewrite the library), and volatile (native DRAM implementation). The authors observe that 1) HW outperforms explicit because HW performs less pointer format conversions 2) SW much worse than HW because dynamic checks causes the branch predictor to mispredict 3) HW has almost no overhead compared to volatile. (I am questioning the HW performance compared to the baseline volatile version. The HW performances seem too good to be true. See question 2.)
Thoughts and Comments
- This solution uses the NVM as a volatile memory, so no persistency, crash consistency etc. I think this makes sense, since the legacy libraries are not written with persistency in the first place.
- This solution only ports libraries and not user code, which can be large as well. That being said, the authors made it very clear that the solution is targeting libraries, so this is more of an observation rather than criticism.
- The fact that they did not need to change a single line of code in the Boost library is impressive. I imagine this work would be useful for companies look for a cheaper DRAM alternative (given that the simulation results hold in real hardware).
Questions
- As shown in Figure 2, why can virtual addresses be pointing to NVM data? Is this not a bad idea?
- (My own) Because in the end relative pointers need to be converted to virtual pointers in order to access a memory location.
Ex.
storeP Rd, Rs, which stores pointer value Rs into memory location Rd. Let us assume that Rd is relative and Rs is virtual. Since Rd is relative, the memory location is on NVM. Thus, Rs needs to be convert to a relative address for it to be useful. In addition, we need to convert Rd, a relative address, to a virtual address in order to access that memory location (we can’t really saymemory[relative address]). So the semantic of the instruction should bememory[ra2va[Rd]]=va2ra[Rs].
- (My own) Because in the end relative pointers need to be converted to virtual pointers in order to access a memory location.
Ex.
- In Figure 11, how can the HW supported version outperform the native volatile version? NVM access are inherently slower than DRAM (at least in the current technology node), so I would expect that applications using NVM as volatile memory to perform worse (if not much worse…) than the original DRAM version.
Sources
[1] C. Ye, Y. Xu, X. Shenz, X. Liaoy, H. Jiny, and Y. Solihin, “Supporting Legacy Libraries on Non-Volatile Memory: A User-Transparent Approach,” ISCA 2021.
[2] https://pmem.io/2015/06/13/accessing-pmem.html
[3] Book: S. Scargall, Programming Persistent Memory: A Comprehensive Guide for Developers, 2020