#3 Shared Memory Consistency Models: A Tutorial
12 Jun 2021
| Link | https://www.hpl.hp.com/techreports/Compaq-DEC/WRL-95-7.pdf |
| Year | 1996 |
Summary
Memory consistency is a formal specification that describes how the hardware system will behave given a sequence of memory operations. Sequential consistency says that 1) each processor must follow their own program order 2) all processors see the same global order, which is some interleave of each processor’s operations. Hardwares supporting sequential consistency must satisfy two requirements: 1) Program order: a processor must ensure that its previous memory operation is complete before executing the next memory operation. In cache based systems, this means that a write must wait for acknowledgements from all other cached copies before proceeding. 2) Write atomicity (only cache based systems): First, writes to the same location need to be serialized. Second, reads on recent writes must be stalled untill all cached copies acknowledge the write.
Details
In order to write correct and efficient code, programmers need to understand how memory hardware behaves when issued read/write commands. Memory consistency serves as an agreement between the programmer and architect. The key realization is that program order != memory execution order. Mechanisms such as out of order execution, cache eviction, and memory controller optimizations all have the potential to reorder memory operations to achieve better performance. Things get more complicated when we have multiple processors/threads.
Sequential Consistency
Almost all lectures/tutorials start with sequential consistency, so here we go. The definition of sequential consistency contains two parts (not “official” definitions, but my own take):
- Each individual processor must follow their own program orders.
- (Only in systems with cache) Globally, all processors must see a single order that is some interleave of operations from each processor.
Part 2 requires atomicity of memory operations, ie. memory operations need to appear to take affect instantaneously with respect to other memory operations. More on this later. As shown in Figure 1, The “needle” provides the interleaving global memory order described in Part 2.
Listing 1 provides two code examples that will behave as expected if our system guarantees sequential consistency. Listing 1(a) requires definition 1 to function as expected. The code implements Dekker’s algorithm. The expected behavior is mutual exlusion, ie. not both P1 and P2 can enter the critical section at the same time. (Yes this code will deadlock, but that is not the point here and deadlock satisfies mutual exclusion). Clearly, mutual exclusion relies on definition 1. If either P1 or P2’s program order is violated, both processors may enter the critical section at the same time. Listing 2(a) requires definition 2 to function as expected. Under seqeuntial consistency, register1 is guranteed to be 1 at the end of the program. This is because definition 2 allows us to assume that the effect of P1’s store to A is seen by P2 and P3 at the same time (atomicity). Of course, memory events do not occur instantaneously. If (P2 sees P1’s store to A && P3 see P2’s store to B) before P3 sees P1’s store to A (How could this happen? Depends on the hardware. More on this later), sequential consistency is violated and register1 is not guranteed to be 1 anymore. This is because not all 3 processes observe the same global order anymore.
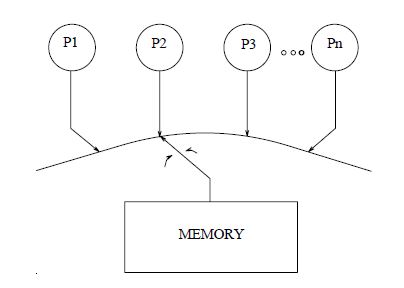
Figure 1: The classic abstraction of sequential consistency.

Listing 1: Code examples that illustrate the sequential consistency requirements.
Sequential consistency is pretty restrictive. Common hardware optimization, with or without caches, can violate sequantial consistency easily. Here are some examples.
Architectures Without Caches
First, we consider write buffer with bypassing capability. The write buffer enables the processor to hide write latencies by inserting write operations into the buffer and proceeding with execution. Bypassing means that the processor’s subsequent reads do not need to wait for write ops in the write buffer to complete (unless the read adress matches the address of a buffered write). Listing 2(a) shows how this can violate sequantial consistency. Since reads may bypass writes, the memory may execute both P1 and P2’s reads first, violating definition 1 (recall that architectures without cache can only violate definition 1). Code breaks :( In Listing 2(b), we enable overlapping writes by adding another memory module. This enables multiple write operations to be services in parallel by different memory modules. However, the interconnect may reorder P1’s write operations, which causes P2 to read the wrong Data value. We can prevent this by forcing Write Head to wait for Write Data to reach the memory module. The last optimization is non-blocking reads, which means that a processor’s subsequent executions may proceed without stalling for the return value of a read operatiion. Listing 2(c) shows one scenario that will violate sequential consistency. P2 can issue Read Data before Read Head returns. If Read Data reaches memory before P1’s writes while Read Head reaches memory after P1’s writes, P2 will end up reading the old value of Data and not 2000.
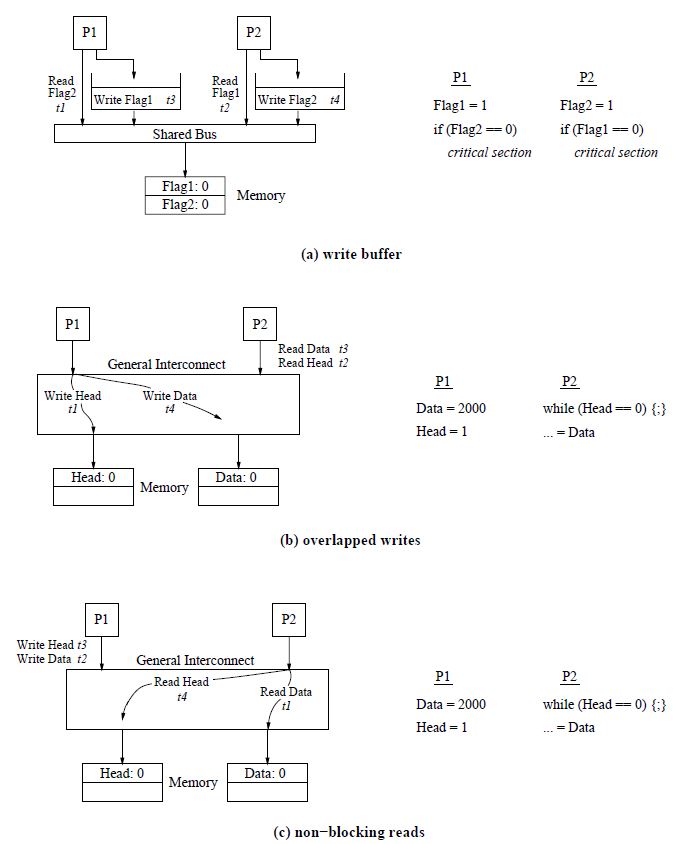
Listing 2: Hardware optimizations that can violate sequential consistency. t1, t2, t3 represent the order in which the memory operation is executed at the memory (not operation issue order).
Architectures With Caches
On top of the reording behaviors described above, caching introduces additional issues. First, to maintain program order, when writing to a line that is replicated in other processor caches, the source processor must wait for acknowledgements from all other caches containing the same data to consider the write to be complete. Consider Listing 2(b) and assume P1 and P2 has their own write through cache. Assume P2 initially has Data in its cache. Then, P1’s write to Head reaches memory but has not updated P2’s cache yet. It is now possible for P2 to read Head’s new value while still having Data’s old cached copy, which violates sequential consistency. One solution is for P1 to require acknowledgement from P2’s cache that it received the Data update before proceeding with the write to Head.
Second, cache operations in mutli-processor systems are inherently non-atomic. To create the illusion of atomicity, we require two conditions: write serialization and stalling reads on recent writes. Write serialization means that all processors must see writes to the same location in the same order. Under sequential consistency, the code in Listing 3 will result in register1 and register2 having the same final value (1 or 2). If write serialization is violated, P3 and P4 may see P1 and P2’s writes to A in different order. This may happen in systems with networks as depicted in Listing 2(b), where the order of delivery is not guaranteed. To satisfy write atomicity, we also need to stall reads on recent writes. An example is depicted in Listing 1(b). Write serialization is not a concern here because we do not have writes to the same location. This program can still violate write atomicity if P2’s write to B reaches P3 before P1’s write to A reaches P3. One potential solution is to stall P2’s read A until all cached copies of A have received P1’s write to A.
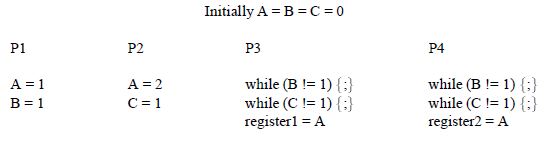
Listing 3: Example illustrating the importance of write serialization.
Relaxed Consistency
Coming soon…
Thoughts and Comments
Questions
Sources
All images are from “Shared Memory Consistency Models: A Tutorial” unless otherwise specified.